Paper Notes: [FAST'03] ARC: A Self-Tuning, Low Overhead Replacement Cache
This article summarizes how the ARC cache replacement algorithm adaptively balances recency and frequency, and explains its advantages over LRU.
ARC is a cache replacement algorithm that performs better than the commonly used LRU algorithm across many workload environments, while its implementation difficulty and algorithmic complexity are close to those of LRU.
The ARC algorithm has the following desirable properties:
It continuously performs dynamic (online) adjustment between recency and frequency
It does not require special parameters (prior knowledge) to be specified in advance
It has a globally optimized strategy (free translation; I am not sure whether this translation is correct. The original term is empirically universal, and the note says the term comes from the LZ77 paper)
It can resist linear scans (scan-resistant) to some extent
The original paper spends considerable space introducing earlier work in which people tried to propose algorithms better than LRU, and then compares them. Due to length and effort constraints, this article skips that part.
Basic Idea
The problem with LRU is that it only considers recency and completely ignores frequency. In general, the cost of storing frequency information is also relatively high. The most fundamental idea of ARC (called DBL below) is to use two LRUs: one, $L_1$, stores data that has been accessed once recently (that is, the traditional LRU), and the other, $L_2$, stores data that has been accessed twice or more recently. This approximation reduces the cost of maintaining frequency. The ultimate goal is to maintain $|L_1| = |L_2| = c$ as much as possible, but the paper does not explain why this should be done. (It is always possible to maintain $|L_1| + |L_2| = 2c$; when $|L_1| < c$, contents in $L_2$ are evicted first to make room for $L_1$.)
We divide the entire Cache into the following two parts:
Cache Directory
Cache Item
The Cache Directory is used for indexing, while the Cache Item represents the content actually in the cache. For the traditional LRU algorithm, the sizes of these two are the same (the number of items indexed by the Directory and the number of contents actually in the cache). For the DBL mentioned above, the sizes of these two are also the same, namely $|L_1| + |L_2| = 2c$. In particular, in DBL, $L_1$ is a traditional LRU with size $c$.
The problem with the DBL algorithm mentioned above is that it uses twice the space of LRU, and it is obvious that it performs better than LRU. Can we use the same amount of space as LRU and obtain better performance? A straightforward idea is to use a Cache Directory of size $2c$ but keep only $c$ Cache Items resident in memory. Then how to choose among these $2c$ index entries becomes a problem. As shown in [figure-1], we split $L_1$ and $L_2$ into $T_1, B_1, T_2, B_2$, respectively. Intuitively, $T_1$ is more valuable than $B_1$, and $T_2$ is more valuable than $B_2$. If we can maintain $|T_1| + |T_2| \le c$, then the elements in $T_1 \cup T_2$ should be kept in the Cache.
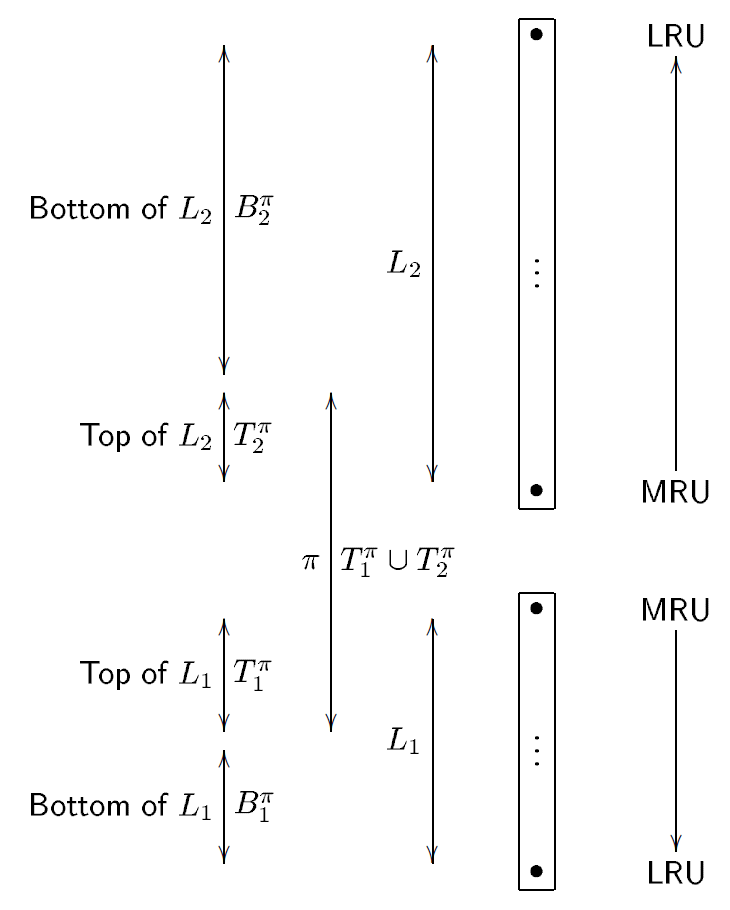
The remaining questions are how to adjust the position of $T_1 \cup T_2$ within $L_1 \cup L_2$ (that is, adjust $|B_1|$ and $|B_2|$), and how to adjust the size allocation between $T_1$ and $T_2$ within $T_1 \cup T_2$. In particular, when $|L_1| = |T_1| = c$, this algorithm is equivalent to LRU. In other words, if adjusted properly, this algorithm can be at least as good as LRU.
The ARC Algorithm
Because we require the property $|L_1| = |L_2| = c$ to be maintained, when adjusting the relationship between $T_1$ and $T_2$, we are effectively adjusting the position of $T_1 \cup T_2$ within $L_1 \cup L_2$. Intuitively, this is like having a fixed-size slider somewhere between $L_1$ and $L_2$, and we adjust the position of this slider. Let $|T_1| = p$; then $|B_1| = |T_2| = c - p$ and $|B_2| = p$.
Next, we need to think about what $B_1$ and $B_2$ mean to us. Recall the DBL mentioned above: $L_1$ means the indexes of cache items that have been hit only once recently, where $T_1$ is the content we keep in the cache, and $B_1$ is the content we do not keep in the cache. Therefore, if a query request hits $B_1$, it means we should treat this hit as a hit in $L_1$, and correspondingly, it indicates that our $|T_1|$ may have been too small and failed to store the data hit this time. In the paper, when $|B_1| \gt |B_2|$, $p$ increases by 1; when $|B_1| < |B_2|$, $p$ increases by $|B_2| / |B_1|$. However, the paper does not explain why it is designed this way.
The complete ARC algorithm is shown in [figure-2], where Cases I-III correspond to DBL hit cases, and Case IV corresponds to the DBL miss case.

Revisiting the Questions
Some questions were mentioned earlier; here we continue to discuss them.
Can the Sizes of $L_1$ and $L_2$ Be Adjusted?
In the current design, $|L_1| = |L_2| = c$. Since we keep at most $|T_1| + |T_2| = c$ items of content, in the extreme case $|L_1| = |T_1| = c$. At this point, further increasing $L_1$ cannot enable any additional adjustment (limited by the Cache size). From this perspective, adjustment between $L_1$ and $L_2$ may not be very meaningful.
However, the paper specifically mentions E. Extra History and discusses this question:
An interesting question is whether we can incorporate more history information in ARC to further improve it.
The paper gives a method that uses additional space, which seems to imply that doing so is useful, but it does not demonstrate or compare how effective this method is.
Why Is the Adjustment of $p$ Not Fixed?
My guess is that when $B_1$ is small, hitting $B_1$ is relatively difficult, so this should receive a boost. But the paper does not give an explanation for why this is done, nor does it provide any comparison.
Scan-Resistant
Intuitively, ARC can resist requests with a scanning pattern, because ARC considers not only recency but also frequency. Specifically, there are the following two reasons:
A scan refreshes the contents of $L_1$, but does not affect the contents of $L_2$
A scan hits $B_2$ more often (compared with $B_1$), so it further reduces $|T_1|$, which in turn makes the impact caused by the scan smaller than when considering only the first point
It Would Feel Like Something Is Missing Without a Summary
Overall, through a relatively clever method, the ARC algorithm significantly improves on the LRU algorithm without significantly increasing implementation cost or algorithmic time complexity. Using LRU to carry data that has recently been encountered more than twice to approximately capture frequency information is a major highlight. The dynamic balancing scheme is intuitively effective, but its details lack strong justification, so I am not sure whether it is an optimal algorithm. For dynamically changing data, it is expected that a dynamic balancing algorithm will outperform a static algorithm.
References
[1] MEGIDDO N, MODHA D S. ARC: A Self-Tuning, Low Overhead Replacement Cache[C]//CHASE J. Proceedings of the {FAST} ’03 Conference on File and Storage Technologies, March 31 - April 2, 2003, Cathedral Hill Hotel, San Francisco, California, {USA}. USENIX, 2003.
[2] NIMROD MEGIDDO, MODHA D S. one up on LRU[J]. ;Login:, 2003, 28(4).