Distributed Storage From Scratch(Easy)
Distributed Storage From Scratch, Introductory Series: Background
Starting from file systems, relational databases, and disk characteristics, this article supplements the Distributed Storage From Scratch series with backgroun…
File Systems and Relational Database Systems
When talking about storage systems, it is impossible to avoid two well-established systems: file systems and relational database systems. These two systems solve critical user problems in a practical way, and they have evolved to be relatively mature. They are important references for implementing a distributed storage system.
Traditional Magnetic Hard Drives
First, we need to understand the physical characteristics of disks, which are the foundation of traditional disk file systems. The physical structure of a mechanical disk is roughly shown in Physical structure of a traditional mechanical disk.
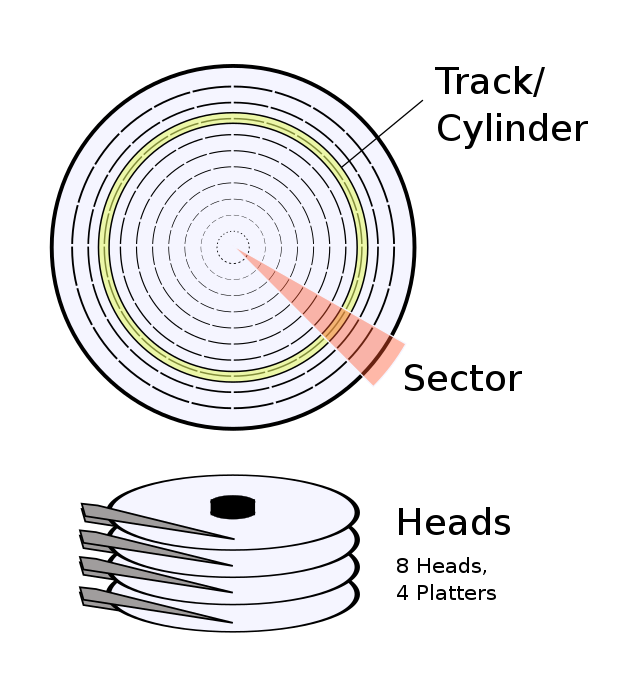
Inside every small black hard-drive enclosure is a set of platters. Each platter has a corresponding actuator arm and magnetic head for reading data from the platter. A disk runs much like an old gramophone:
The platter keeps rotating continuously.
First, the actuator arm lifts and moves to the appropriate track position.
Then the actuator arm lowers, and the magnetic head reads the data recorded on the platter.
Obviously, when a disk reads data, it has to pay a relatively high cost to find the location of the data it wants to read. The main costs are:
Lifting the actuator arm, moving it to the target track, and lowering it again.
Waiting for the platter to rotate to the starting position of the target data.
However, once the location of the data to be read has been found, the cost of reading a contiguous range of data is relatively low.
The relevant comparison data is shown in Latency numbers every programmer should know (2019)[1].

Traditional Disk File Systems
I assume everyone is already familiar with the interfaces provided by file systems, so I will not spend much time introducing file-system interfaces here.[2]
Traditional disk file systems mainly solve the problem of how to organize data on mechanical disks so that data can be accessed safely, conveniently, and quickly. Their basic principles are as follows[3]:
Treat the disk as a sequence of contiguous blocks, where each block has a fixed size (as shown in Physical layout of the EXT2 file system).
Use some of these blocks to store directory data, and other blocks to store the actual data.
Treat files as leaf nodes in the directory data, whose contents are a sequence of pointers to the actual data blocks (as shown in EXT2 directory).
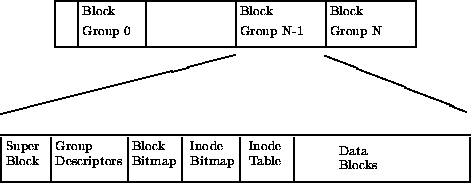
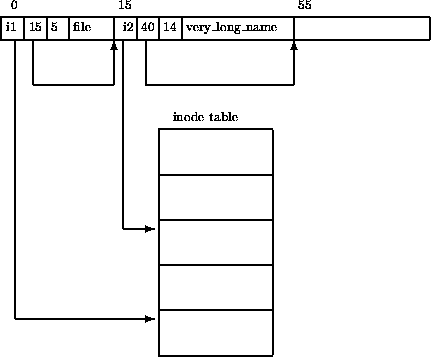
When designing a storage system, we can also refer to this approach: store the actual data in a sequence of data blocks, and then build indexes over that data for fast access to the actual data.
Traditional Relational Database Systems
The overall architecture of a traditional relational database is roughly shown in Database system architecture diagram.
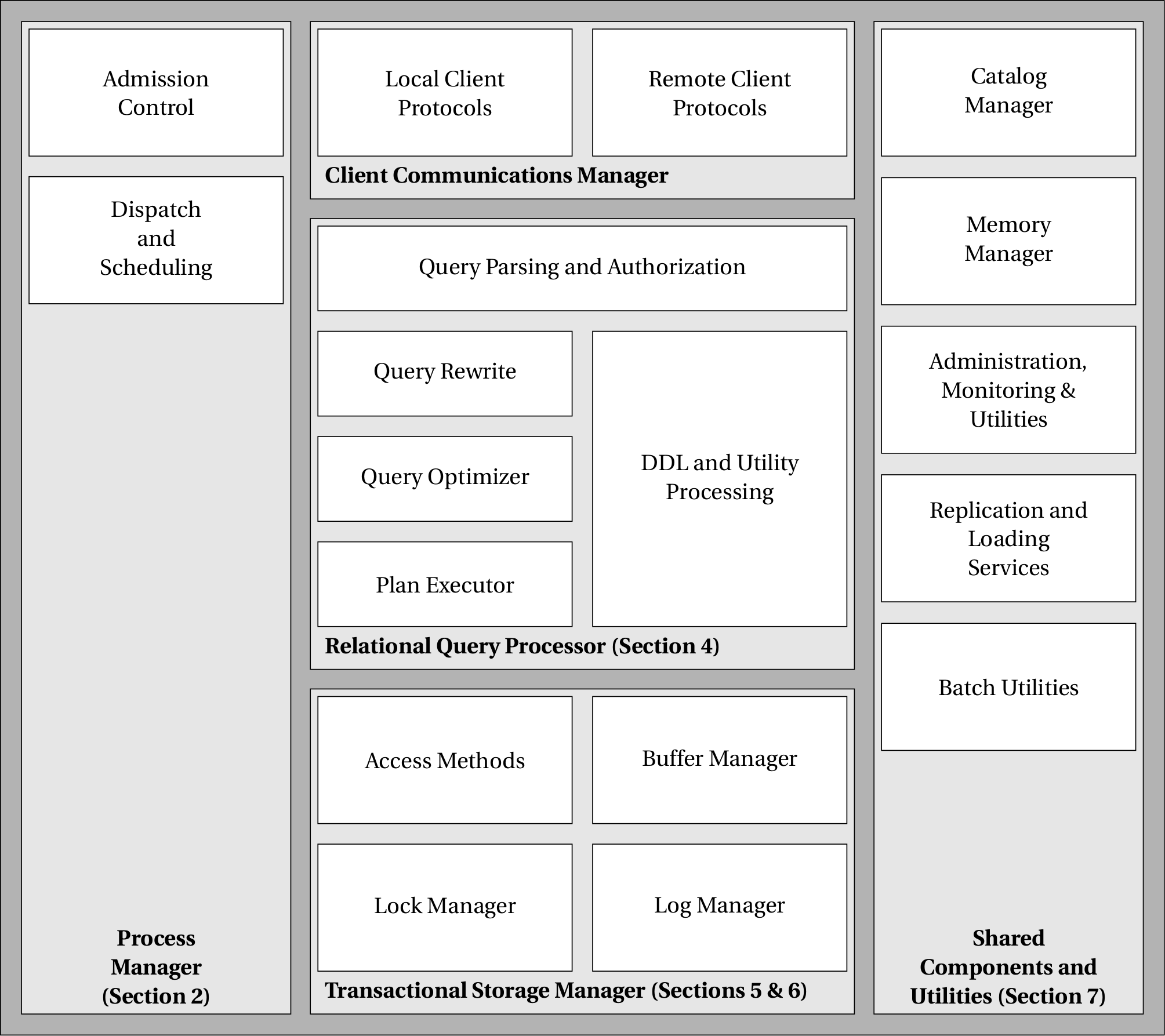
Take a single request to the database as an example:
First, a persistent connection must be established with the database. This part is handled by the topmost component, the Client Communications Manager. Databases usually need to support different protocols, such as ODBC and JDBC, TCP, and local pipes.
After the user connection is established, the system needs to verify whether the user has permission to access the target resource (Admission Control). If the check passes, thread resources are allocated to the user (Dispatch and Scheduling).
Next, the user’s request enters the core part of the database and is processed by the Relational Query Processor component.
The user’s SQL query is first parsed into an internal representation, usually an expression tree corresponding to relational algebra.
Next, the SQL query is optimized. Before this, there is generally a Rewrite step that performs some preprocessing on the query to simplify the logic of the Optimizer.
The optimized SQL query may contain multiple Operators. The results produced by these Operators also need to be combined and pipelined, and this work is performed by the Plan Executor.
Operator execution requires support from the lower layers of the database. This functionality is handled by the bottommost component, the Transactional Storage Manager.
During the entire request-processing period, metadata such as table schemas and statistics about table contents may need to be obtained from the Catalog Manager.
In the target system we expect to implement, the points that need attention include:
Access control (Admission Control), which includes several aspects:
Prevent users from operating on data that does not belong to them.
Prevent one user from consuming too many resources and causing other users to be unable to access data normally.
Request dispatching and scheduling (Dispatch and Scheduling).
Metadata management (Catalog Manager).
Management of the overall storage layer (Transactional Storage Manager).
Due to space constraints, I will not expand on these topics here. Interested readers can refer to Paper Notes: [FTNDB'07] Architecture of a Database System.
NoSQL and NewSQL
Traditional relational databases went through a fairly long period of prosperity. However, as the times have changed, the amount of data we generate and need to process has grown dramatically. According to statistics from DOMO, the growth of the internet population is shown in Internet population growth trend. One problem brought by the growth in data volume is that this data is difficult, or impossible, to store and process effectively on a single machine.
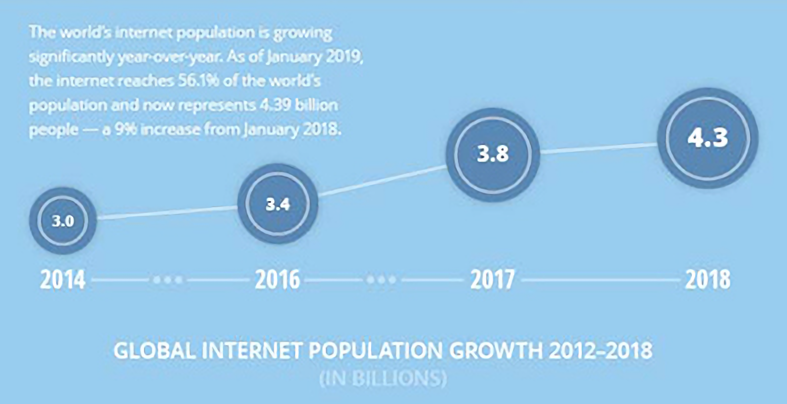
A relatively common approach is to distribute data across multiple machines for storage and processing. In traditional databases, the distributed solution is colloquially known as database and table sharding. In practice, it involves two distinct forms of partitioning:
Place different tables from the same database on different machines.
Place different rows from the same table on different machines.
For the former, as long as cross-table queries such as Join operations are not performed, the database can be used like a single-machine database. Unfortunately, the main use case for traditional databases is querying based on relationships between tables, so this limitation is still significant. On the other hand, as data continues to grow, we still face scenarios where even placing one table on one machine becomes difficult. At that point, different rows in the table must be placed on different machines. After doing this, even some simple Scan operations must be executed on multiple machines, and their results must then be summarized, or aggregated, before they can be used.
On the surface, this approach seems to solve the problem. In reality, it completely destroys the abstraction provided by the SQL query interface. Originally, we only needed to provide SQL statements; the database system would internally optimize those SQL statements and complete the entire query operation. Now, however, we not only have to provide SQL statements, but also have to implement some functions involved in SQL execution, such as task dispatching and aggregation. These functions should originally be handled by SQL execution engines such as Spark SQL, Flink SQL, and so on. Everything discussed above involves only ordinary query functionality and does not even touch data writes or transactions.
This means that, in practice, we no longer need the SQL-layer functionality provided by a single-machine system. We only need the single-machine storage system to provide storage-related functionality. All SQL-layer work should be completed by so-called database middleware.
On the other hand, we also impose new requirements on the single-machine storage system. Because we use more machines to store our data and provide services, the failure rate of the overall system increases (\(1 - (1 - \text{single-machine failure rate})^\text{number of machines} > \text{single-machine failure rate}\). As a note for readers who are less comfortable with math: when \(0 < n < 1\), \(n^k < n\)). We need single-machine storage systems to be able to form mutually redundant systems, so that when one machine fails, data can be automatically recovered from another machine.
Against this background, the NoSQL movement unfolded in full swing. On the surface, it looked as if everyone had completely abandoned SQL, a storage system that had been proven highly practical and had become relatively mature, and had regressed all the way back to the era of using raw storage devices directly. In reality, it was a rebirth of the entire storage system as it moved from single-machine systems to distributed systems.
Although the overall direction had been set, the concrete implementation approaches varied. Some people chose to implement a distributed file system. Ideally, the performance of a distributed file system would be comparable to that of a local file system. In that case, upper-layer applications would need almost no changes: they could run directly on the distributed file system and enjoy nearly unlimited storage capacity. Unfortunately, the random-access performance of such systems is still difficult to make comparable to that of local file systems, not to mention that the emergence of SSDs widened the gap even further. On the other hand, even if the storage problem were solved, the compute performance of a single machine would still be unable to meet the requirements of this volume of data. Some people chose to implement a distributed shared-memory system. This requirement is actually even more demanding than that of a distributed file system, so it failed for similar reasons. Others chose to implement distributed object storage systems, also called key-value storage systems. This model is simple enough, but in practice it fits the model of magnetic disks: storage space consists of a sequence of Blocks. As a result, it has been widely adopted and has developed well.
The approaches described above are, in practice, compromise solutions adopted before people had time to implement SQL. Essentially, they first set SQL aside, solved more primitive problems, and then still wanted to add SQL back later. For these approaches, calling them NoSQL is not inappropriate. However, in the new era, some genuinely new methods have also emerged, and these significantly different methods claim to be NewSQL or Not only SQL. For example, the performance of column-oriented storage databases in some analytical query scenarios may be 10 to 100 times that of traditional databases, and the TPS (Transactions Per Second) performance of in-memory databases may be 10 to 100 times that of traditional databases, and so on[4].