Paper Notes: [OSDI'16] Slicer: Auto-Sharding for Datacenter Applications
This article introduces the control plane, client-side routing, and load-balancing design of Google Slicer, an auto-sharding component.
Slicer [1] is an infrastructure component used inside Google that integrates with the RPC framework and helps applications scale through sharding. The paper notes several ways in which it differs from other papers on general-purpose sharding frameworks:
Separation of the control side and the data side
An efficient load-balancing algorithm that provides strong load-balancing efficiency while minimizing key churn as much as possible
Evaluation results from a large-scale production environment
In my view, its distinctive aspects include:
It extracts the sharding problem, which storage systems often need to solve, into an infrastructure component integrated with the RPC framework. This idea is interesting in itself.
On top of sharding, it can support some fairly special capabilities, such as:
Guiding applications to redistribute shards, similar to rehashing
Supporting shard splitting and merging
Masking failed nodes and guiding applications to move the load from failed nodes to healthy nodes so they can continue serving requests
Increasing the number of replicas for hot spots to handle higher read load. The paper mentions this idea, but it appears not to have been implemented.
Providing lease control at key-range granularity. The paper uses lease control to ensure that at most one service provider exists for a key range at any time, but this feature was not used in production.
Basic Idea and Overall Architecture
Overall, Slicer improves on Centrifuge [2]. It consists of three main parts, as shown in Abstract Slicer architecture:
Slicer Service: the core part of the system, responsible for controlling shard distribution and serving queries
Clerk: the part embedded in the client-side RPC library, responsible for interacting with the Slicer Service and guiding RPC request routing
Slicelet: the part embedded on the server side, responsible for interacting with the Slicer Service and accepting the Slicer Service’s control over shard redistribution
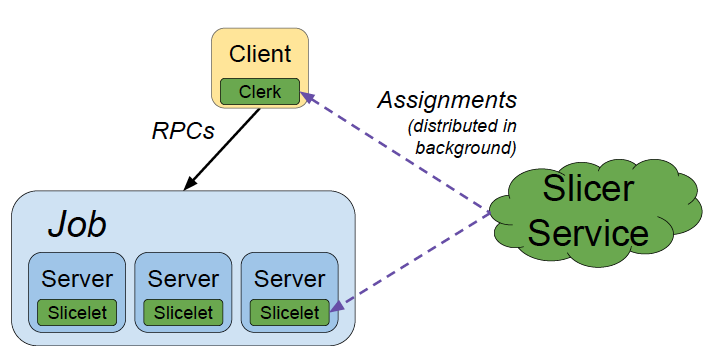
The core idea here is that the Slicer Service controls the mapping between Logical Shards, which are key ranges in the paper, and Physical Servers, which the paper calls tasks, and then makes appropriate adjustments based on feedback.
For availability reasons, Slicer further splits the Slicer Service as shown in Slicer backend service architecture:
Assigner: responsible for adjusting and controlling the mapping between Logical Shards and Physical Servers
Distributor: responsible for querying, or passively distributing, the Assigner’s control results
Backup Distributor: the fallback plan when the Assigner fails
Store: the reliable storage behind the Assigner
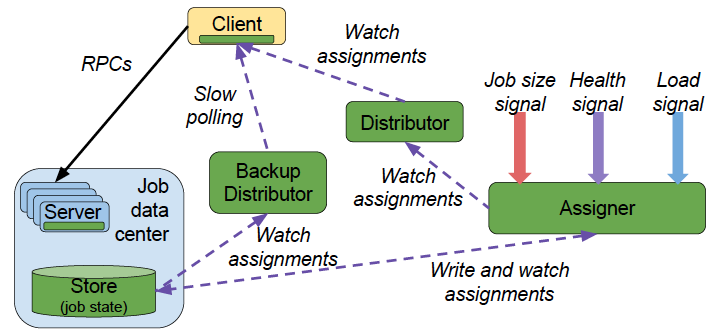
Another additional benefit of this design is that if the Client and the Assigner are in different datacenters, the Distributor and the Client can be deployed in the same datacenter, saving cross-datacenter traffic and improving efficiency because the Distributor has its own cache.
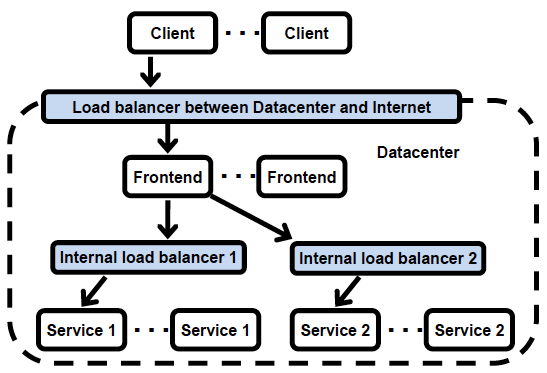
Another common cross-datacenter strategy is to use a traditional SLB for cross-datacenter forwarding, as shown in Centrifuge cross datacenter.
Load Balancing
Slicer uses RPC Metrics data as input to evaluate load balancing across Shards and then make adjustments. From the architecture above, we can see that an adjustment, or Assignment, becomes effective in an eventually consistent way.
Slicer’s load balancing considers the following aspects:
Keeping peak load as low as possible
Reducing key churn during adjustment
Merging and splitting key ranges
However, it does not consider increasing the number of replicas for some Logical Shards based on load, or automatically adjusting Physical Server resources.
First, consider how to abstract the load metric. In Slicer, the Load imbalance value is used as an empirical metric to represent the load-balancing condition of the whole system. If the load of a Physical Server is defined as the number of Logical Shards for which it is responsible, then the Load imbalance value is the ratio between the maximum load and the average load across the whole system.
Personally, I think this empirical metric looks somewhat problematic:
It assumes that load in the whole system is uniformly distributed over keys, which may not hold in practice even for a hash-distributed key space.
It assumes that Logical Shards have consistent sizes, but later the system also splits and merges Logical Shards.
Next is how to abstract key churn. In Slicer, the proportion of keys reassigned in one round of adjustment is used as the key churn metric. Slicer does not reassign key ranges for Physical Servers with low CPU load, thereby avoiding the key churn cost caused by over-optimization.
Slicer’s load-balancing algorithm is also empirically derived, and the specific numbers for some thresholds are also empirical, so I will not go into detail here.
Strong Consistency
Slicer implements strong consistency through a lease mechanism. Here, strong consistency means that at most one Physical Server serves a key at any given time. It is important to note that the lease mechanism implies a clock-synchronization requirement. Obviously, we cannot provide lease management for every key. A simple approach is to manage leases at key-range granularity. Slicer goes one step further: it can complete lease management using at most three Chubby locks. Because lease management is performed by Chubby, even a Slicer failure does not affect user services.
job lease: first, a lock is needed to ensure that only one Assigner is responsible for the entire assignment at any given time.
guard lease: the Assigner generates a lease for each round of assignment. Only a slicelet that has obtained the lease permission may serve requests. In this way, when the assignment is updated, a slicelet holding stale information stops serving requests, avoiding the situation where multiple slicelets serve the same key because of unsynchronized information.
bridge lease: if only the guard lease were used, every round of assignment would cause the guard lease for the entire service to expire as a whole. However, each round of assignment obviously changes the distribution of only a small portion of the key ranges, and the unchanged parts should not be affected. Therefore, for the unchanged part of the assignment, Slicer introduces a bridge lease so it is not affected by guard lease expiration.
Personally, I think this idea is still quite interesting. It means Slicer can control both assignment and leader election. As long as users implement their own replication mechanism, they can easily build a stateful service.
The strong-consistency-related APIs in Slicelet are as follows:
Opaque getSliceKeyHandle(String key);
boolean isAssignedContinuously(Opaque handle);The usage is similar to the following, based on [2]:
boolean Subscribe(String key, String address) {
// (1) Check that this is the correct node
Opaque handle = getSliceKeyHandle(key);
if (handle == null) return false;
// (2) Perform arbitrary operation on this state;
// store lease number with any created state
// in this case, simply add subscription
this.subscriptionLists[key].add(address);
// (3) Check that lease has been continuously held;
// if so, return result
if (!isAssignedContinuously(handle)) {
// Rollback subscription
this.subscriptionLists[key].remove(address);
return false;
}
// Commit subscription
return true;
}Comparison with Consistent Hashing
A major problem with consistent hashing is that its hash algorithm is fixed. If the data distribution does not match the assumptions of the hash algorithm, there is almost no opportunity to adjust it. This makes it less suitable in load-balancing scenarios. On the other hand, consistent hashing is also a major limitation if you want to support asymmetric replica counts, for example, when some key ranges have only two replicas while some hot key ranges have 200 replicas.
References
[1] ADYA A, MYERS D, HOWELL J, etc. Slicer : Auto-Sharding for Datacenter Applications[J]. Osdi, 2016: 739–754.
[2] ADYA A, DUNAGAN J, WOLMAN A. Centrifuge: Integrated Lease Management and Partitioning for Cloud Services[C]. NSDI’10 Proceedings of the 7th USENIX conference on Networked systems design and implementation. USENIX Association, 2010.