Hash Table Summary and Discussion of Advanced Topics
This article summarizes common issues in hash tables, such as collisions and resizing, and discusses advanced topics such as perfect hashing.
A hash table is a data structure commonly used in fast lookup scenarios. This article provides a limited summary and discussion of its main issues and advanced approaches for addressing them:
The load may not be sufficiently balanced, in which case hash collisions occur and degrade hash table performance.
When the load is high, performance degrades if the space is not expanded; if the space is expanded, the (instantaneous) cost of expansion is usually high.
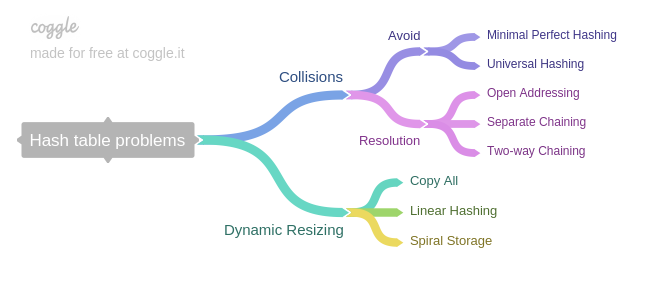
First, let’s review the mathematical model of a hash table:
The space that contains all data is the set \(S\)
The set of data stored through the hash table is \(U\)
The set of indices for all hash buckets is \(R\)
Elements in \(S\) are mapped to the set \(R\) in some way; denote this function as \(h\)
In general, the size of \(S\) is much larger than that of \(R\), but the size of the data set \(U\) stored through the hash table is not drastically different from the size of \(R\).
If \(x \in S, y \in S\) and \(x \ne y \land h(x) = h(y)\), then \(x\) and \(y\) are said to collide.
If \(h\) can map \(U\) injectively into \(R\), this is called perfect hashing. This means that the size of \(U\) is less than or equal to the size of \(R\). In particular, when the size of \(U\) is equal to the size of \(R\), this is called minimal perfect hashing.
If \(U\) is given in advance and will no longer change, this is called a static hash table; otherwise, it is called a dynamic hash table.
Hash Collisions
There are two types of solutions for hash collisions:
Collision avoidance
Collision resolution
Collision Avoidance
If the hash function \(h\) is chosen well enough, and the size of \(U\) is less than or equal to the size of \(R\), it may be possible to achieve perfect hashing. For static hash tables, deterministic strategies [1] can find such an \(h\) and achieve minimal perfect hashing. For dynamic hash tables, because we cannot predict the distribution of elements in \(U\), we cannot design \(h\) in advance to achieve perfect hashing. In particular, because the elements in \(U\) change, \(U \subset S\), and the size of \(S\) is much larger than the size of \(R\), for a hash function \(h\) constructed with a deterministic strategy, there is always an adversarial set \(U\) that can make hash collisions as numerous as possible. Therefore, for dynamic hash tables, a nondeterministic strategy must be used to construct the hash function \(h\) before it is possible to guarantee avoidance of hash collisions. This problem is called the Dynamic Perfect Hashing problem. One feasible approach is to prepare a family of hash functions in advance and randomly choose one hash function from it during use. Intuitively, this family of hash functions should have some property such that inputs with the same distribution do not produce outputs with the same distribution. In this way, an adversarial strategy against one specific hash function will not work against other hash functions, so randomly selecting a hash function can resist deterministic adversarial strategies. Of course, this raises a question: during lookup, how do we know which hash function to use? This question is discussed further later in Two-way Chaining under Collision Resolution.
If there exists a set of hash functions \(H = \{h: U \rightarrow R\}\) satisfying \(\forall x, y \in U, x \ne y: \Pr_{h \in H}[h(x) = h(y)] \le 1/{|R|}\), then \(H\) is called a universal hashing family [2]. The meaning of this mathematical expression is that if any two distinct elements \(x, y\) are chosen from \(U\) and any hash function \(h\) is chosen from \(H\), then \(h(x), h(y)\) are independent (uniformly distributed).
A stronger form of universal hashing is universalk hashing [3], which must satisfy the following condition: given k pairwise distinct elements \((x_1, ..., x_k) \in U^k\) and k hash values (which do not need to be pairwise distinct) \((y_1, ..., y_k) \in R^k\), we have
This stronger form is usually difficult to achieve, so we sometimes choose its relaxed form, \((\mu, k)\)-universal:
The closer \(\mu\) is to 1, the better.
Collision Resolution
From the discussion above, we can see that perfect hashing is difficult to achieve for dynamic hash tables, so we must consider how to handle hash collisions. Common collision resolution strategies include:
Open Addressing
Separate Chaining
Two-way Chaining
Open Addressing
Open Addressing is a common collision resolution strategy. Its common sub-strategies include:
Linear probing
Quadratic probing
Double hashing
Among them, Linear probing has the best performance because it is cache-friendly, so it is used relatively often. Linear probing can lead to collision clustering; to avoid this phenomenon, the Quadratic probing strategy is sometimes used. Quadratic probing can also be defeated by adversarial strategies, so Double hashing is sometimes used together with Universal hashing to obtain better results.
Separate Chaining
The performance of Open Addressing drops sharply when the load factor is high. To handle this situation, the Separate Chaining strategy is also commonly used. Separate Chaining generally uses linked lists, and sometimes also uses search tree structures.
Two-way Chaining
Two-way Chaining is like Double hashing. The difference is that Double hashing uses one hash table, while Two-way Chaining uses two hash tables, T1 and T2. During insertion, the element is inserted into whichever of \(T[h_1(x)]\) and \(T[h_2(x)]\) has fewer loaded elements. Lookup needs to access both hash tables.
Cuckoo Hashing
Cuckoo Hashing [4] is an advanced version of Two-way Chaining. It also uses two hash tables, but it no longer performs Chaining; instead, it uses eviction. The algorithm is as follows:
procedure insert(x)
if lookup(x) then return
loop MaxLoop times
x ↔ T1[h1(x)]
if x = ⊥ then return
x ↔ T2[h2(x)]
if x = ⊥ then return
end loop
rehash(); insert(x)
endCuckoo Hashing does not use Chaining, which means it is a Dynamic Perfect Hashing scheme.
P.S. The Cuckoo Hashing paper [4] further optimizes the \((\mu, k)\)-universal hash function family it uses.
Dynamic Resizing
As the load factor of a hash table rises, the probability of hash collisions continues to increase until, when the load factor exceeds 1, hash collisions necessarily occur (the pigeonhole principle). For dynamic hash tables, because the size of \(U\) cannot be known in advance, the size of the hash table must be adjusted dynamically. A common strategy is to linearly expand the hash table to several times its original size after the load factor exceeds some threshold, and to linearly shrink the hash table to some fraction of its original size when the load factor falls below some threshold. The reason for using two thresholds is to avoid oscillation. Because \(R\) changes, the corresponding hash function must also change. When resizing, memory is allocated separately, and then all elements in the original hash table are rehashed and stored in the new hash table. This strategy is called the Copy All strategy. Although this operation can be amortized into insertion operations so that the overall amortized time complexity remains constant, this strategy can cause long pauses. To improve this issue, there are other improved strategies [5], among which the better-known ones are:
Linear Hashing
Spiral Storage
Extendible Hashing
The fundamental reason a hash table cannot grow smoothly is rehashing. As long as \(R\) can be adjusted without rehashing, this problem can be solved.
Linear Hashing
Linear Hashing [5][6] uses two hash functions at the same time to solve the dynamic resizing problem. Consider the following family of hash functions:
For any given \(x \in U\), either \(h_i(x) = h_{i - 1}(x)\) or \(h_i(c) = h_{i - 1}(c) + 2^{i - 1} N\). In general, simple modulo operations can satisfy this requirement.
When the hash array needs to expand, expansion proceeds from front to back, and the index of the bucket currently being expanded is marked as p. For positions before p, \(h_{i + 1}\) is used; for p and positions after it, \(h_i\) is still used. In this way, expansion can be very smooth: each operation expands only one bucket, without needing to rehash all elements. However, this approach has a drawback: a bucket at a relatively later position may remain very crowded, and only after many insertions will this bucket be expanded to mitigate the performance degradation. Spiral Storage handles this problem better.
Spiral Storage
Spiral Storage [5] always places more load at the front of the hash table, rather than distributing the load uniformly across the entire hash table. In this way, even though, like Linear Hashing, bucket splitting always starts from the head of the hash table, there is no problem of failing to handle very full buckets promptly.
The idea of Spiral Storage is as follows. The load of the hash table gradually decreases from front to back; when expanding, the elements in the bucket at the head of the table need to be distributed into multiple new buckets and added to the end of the hash table, while still preserving the property that the load gradually decreases from front to back. Suppose that each time one bucket is removed from the head of the table, d new buckets are added; d is called the growth factor of the hash table. Considering that the hash table grows nonlinearly, a nonlinear-growing family of hash functions should be used to map \(U\) to \(R\). It is easy to see that the exponential function satisfies this property. To satisfy the property that the load gradually decreases, \(u \in U\) can first be uniformly mapped to \(x \in [S, S + 1)\), and then the exponential function \(y = d^x \in R\) can be used. The size of \(R\) grows exponentially as \(S\) changes, and the load distribution of the elements in it decreases exponentially. When the hash table expands, elements that were originally in \(y = d^x, x \in [S, S')\) are mapped to the new interval \(y = d^x, x \in [S + 1, S' + 1)\), whose size has grown by d.
The paper [5] describes the concrete implementation details of Spiral Storage and some optimization methods.
Extendible Hashing
Extendible Hashing [7] stores buckets and bucket indices separately. It uses the prefix of the key corresponding to a bucket to index it, so when expanding the size of the hash table, it is only necessary to adjust the index portion without copying all objects.
Usage Scenarios
Single-Machine Scenarios
In scenarios such as Facebook F4, a read-only storage service, or Index Serving scenarios with batch updates, the Minimal Perfect Hashing strategy is suitable.
For dynamic hash table usage scenarios, if the data distribution can be known in advance or partially known, the hash function can be designed specifically to achieve perfect hashing as much as possible.
If there is no additional information about the data, only collision avoidance strategies can be considered. When a low load factor can be guaranteed, Linear Probing should be chosen as much as possible to make good use of the cache. When the load factor cannot be guaranteed, if worst-case guarantees are needed, the strategy of Separate Chaining with balanced search trees should be considered, or simply do not use a hash table. If a high load factor is desired, performance degradation should not be too severe, and some long-tail latency is acceptable, Cuckoo Hashing can be considered.
For dynamic resizing of hash tables, the Copy All strategy is generally chosen, because it imposes the fewest restrictions on the hash function and is the easiest to implement. Personally, I feel that Spiral Storage is somewhat better than Linear Hashing, for the reasons explained above in [spiral-better]. Google has an open-source implementation of Spiral Storage: https://code.google.com/p/sparsehash/ . PostgreSQL uses Linear Hashing; see https://www.postgresql.org/docs/8.0/static/sql-createindex.html .
Multi-Machine Scenarios
Hash function selection is the same as in single-machine scenarios. Here we discuss only the dynamic resizing problem.
Although there were early attempts to extend Linear Hashing and Extendible Hashing to multiple machines [8][9], they were eventually dominated by consistent hashing. In multi-machine scenarios, because single-point bottlenecks are undesirable, P2P structures are used, and the larger problem is how to quickly match a request to the node that actually stores the data. This problem is categorized as how to self-organize peer nodes into some structure and perform message routing on top of it. For a summary of this area, see Paper Notes: Some Surveys on P2P. The time complexity of these routing algorithms is generally at the \(\mathcal{O}(\log n)\) level. For fast lookup scenarios in LAN environments, especially when using hash tables, we generally expect constant-level time complexity. For this, refer to [10][11], or simply cache the mapping information for all nodes.
Other
Because hash tables generally need to maintain a relatively low load factor, elements become very sparse when the hash table is large. If scan operations need to be supported, it is necessary to consider establishing links among non-empty buckets.
If computational complexity is not a concern, cryptographic hash functions can be used to obtain relatively uniform results.
References
[1] Martin Dietzfelbinger. (2007). Design Strategies for Minimal Perfect Hash Functions. Stochastic Algorithms: Foundations and Applications. SAGA 2007. Lecture Notes in Computer Science, vol 4665. DOI:https://doi.org/10.1007/978-3-540-74871-7_2
[2] Carter, J. L., & Wegman, M. N. (1979). Universal classes of hash functions. Journal of Computer and System Sciences, 18(2), 143–154. DOI:https://doi.org/10.1016/0022-0000(79)90044-8
[3] Wegman, M. N., & Carter, J. L. (1981). New hash functions and their use in authentication and set equality. Journal of Computer and System Sciences, 22(3), 265–279. DOI:https://doi.org/10.1016/0022-0000(81)90033-7
[4] Pagh, R., & Rodler, F. F. (2004). Cuckoo hashing. Journal of Algorithms, 51(2), 122–144. https://doi.org/10.1016/J.JALGOR.2003.12.002
[5] Larson, P.-A. (1988). Dynamic hash tables. Communications of the ACM, 31(4), 446–457. https://doi.org/10.1145/42404.42410
[6] Hiemstra, D., Kushmerick, N., Domeniconi, C., Paice, C. D., Carroll, M. W., Jensen, C. S., … Mankovskii, S. (2009). Linear Hashing. In Encyclopedia of Database Systems (Vol. 0, pp. 1619–1622). Boston, MA: Springer US. https://doi.org/10.1007/978-0-387-39940-9_742
[7] Ronald Fagin, Jurg Nievergelt, Nicholas Pippenger, and H. Raymond Strong. 1979. Extendible hashing — a fast access method for dynamic files. ACM Trans. Database Syst. 4, 3 (1979), 315–344. DOI:https://doi.org/10.1145/320083.320092
[8] Witold Litwin, Marie-Anne Neimat, and Donovan A Schneider. 1993. LH*: Linear Hashing for distributed files. Proc. 1993 ACM SIGMOD Int. Conf. Manag. data (1993), 327–336. DOI:https://doi.org/10.1145/170035.170084
[9] Victoria Hilford, Farokh B. Bastani, and Bojan Cukic. 1997. EH* - Extendible Hashing in a distributed environment. Proc. - IEEE Comput. Soc. Int. Comput. Softw. Appl. Conf. (1997).
[10] Venugopalan Ramasubramanian and Emin Gun Sirer. 2004. Beehive: O(1)lookup performance for power-law query distributions in peer-to-peer overlays. System 1, 1 (2004), 8. Retrieved from http://portal.acm.org/citation.cfm?id=1251175.1251183
[11] Tonglin Li, Xiaobing Zhou, Kevin Brandstatter, Dongfang Zhao, Ke Wang, Anupam Rajendran, Zhao Zhang, and Ioan Raicu. 2013. ZHT: A light-weight reliable persistent dynamic scalable zero-hop distributed hash table. Proc. - IEEE 27th Int. Parallel Distrib. Process. Symp. IPDPS 2013 (2013), 775–787. DOI:https://doi.org/10.1109/IPDPS.2013.110
[12] Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. 2007. Dynamo: Amazon’s Highly Available Key-value Store. Proc. Symp. Oper. Syst. Princ. (2007), 205–220. DOI:https://doi.org/10.1145/1323293.1294281
[13] Vahab Mirrokni, Mikkel Thorup, and Morteza Zadimoghaddam. 2016. Consistent Hashing with Bounded Loads. (2016), 587–604. Retrieved from http://arxiv.org/abs/1608.01350
Addendum
Recently I happened to see two good articles: