Paper Notes: [OSDI'10] Large-scale Incremental Processing Using Distributed Transactions and Notifications
This article outlines how Google Percolator implements cross-row transactions and reliable notifications on top of Bigtable, with a focus on the transaction co…
Percolator[1] is based on Bigtable[2]. Without changing Bigtable’s own implementation, it implements cross-row transactions at the Snapshot Isolation level through row-level transactions and multi-version control. The paper also describes a reliable notification mechanism implemented on top of Bigtable.
What is distinctive is that, when implementing these two features, Percolator does not intrusively modify Bigtable’s implementation. Instead, it wraps Bigtable externally to provide them. In some cases this is a very convenient approach, but it usually incurs a performance cost.
This article covers only the transaction-related parts of Percolator.
Background
Bigtable’s data model and transaction support
First, let’s review Bigtable’s data model:
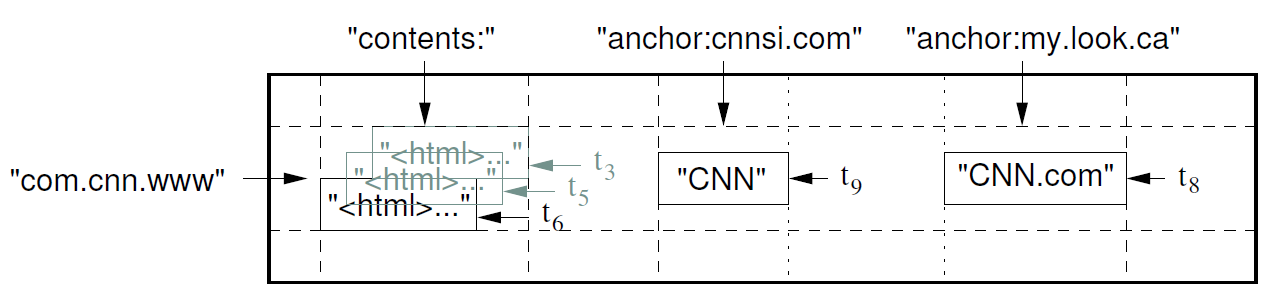
As shown above, data can be identified by the following hierarchy:
row name, such as
com.cnn.wwwcolumn families, such as
anchorcolumn, such as
contents:andanchor:cnnsi.comtimestamp, such as $t_3$, $t_5$, and $t_6$
Introduction to Snapshot Isolation
[3] informally describes Snapshot Isolation. In brief, a transaction under Snapshot Isolation has two important time points: Start-Timestamp and Commit-Timestamp. When the transaction starts, that is, at the Start-Timestamp, it takes a snapshot of the data in the entire system. All data read during the transaction and all changes written by the transaction come from this snapshot. At commit time, that is, at the Commit-Timestamp, if another transaction has already committed, this transaction aborts; otherwise, it succeeds.
There are many related topics around Snapshot Isolation, including the following major areas:
Strengthening isolation: One-copy Snapshot Isolation and Serializable Snapshot Isolation
Various variants and optimizations
Optimizations combined with new hardware
For related topics, see: Snapshot Isolation Survey, Paper Notes: [CONCUR'15] A Framework for Transactional Consistency Models with Atomic Visibility, and CAP, ACID, What Can We Do?.
P.S. For the implementation of MVCC in Postgres, see [10]. [3] mentions that Snapshot Isolation is an extension of the Multiversion Mixed Method in [7]. However, Snapshot Isolation can also be implemented in other ways. For example, [11] provides an approach that implements Snapshot Isolation using read-write locks.
How Percolator implements cross-row transactions
Percolator relies on the underlying BigTable implementation for multi-versioning and row-level transactions, and implements cross-row transactions on that basis.
Main process
Assume there is a Timestamp Oracle Service that can provide monotonically increasing timestamps. Bigtable Transaction provides strongly consistent transactions within a row. Bigtable uses timestamps provided by the Timestamp Oracle Service as cell version numbers. Based on these facilities, we introduce how Percolator Transaction is implemented.
When a Percolator Transaction starts, it obtains a timestamp, the Start-Timestamp.
It enters the read phase.
When issuing a read request, it always obtains the value of the most recent committed version before the Start-Timestamp.
When issuing a write request, it always buffers the write request locally.
When a Percolator Transaction commits:
It enters the locking phase and locks all cells affected by write requests by writing a special cell.
It obtains a timestamp, the Commit-Timestamp.
It enters the commit phase, uses the Commit-Timestamp as the write version, flushes locally buffered write requests to remote storage, and removes the locks on the affected cells.
In the process above, both read requests and write requests require support from Bigtable row-level transactions.
Because BigTable does not support true row-level locks, the lock here is implemented using a special column: c:lock (the : here can easily be ambiguous. In BigTable, : separates ColumnFamily and ColumnName, so you can think of this as using another special symbol as the separator, such as cf:cn+lock). As a result, the original data also needs to change accordingly: by convention, the column c:data stores the real data and its different versions. Because we want to support cross-row transactions, when a Percolator transaction eventually commits, we also need a special column to mark the commit: c:write.
Percolator also makes some changes to avoid assigning a unique identifier to every Percolator transaction. When locking, it arbitrarily designates the cell of one write request as the primary; this lock is the primary lock. The other locks in the transaction are secondary locks and point to this primary lock. This design effectively uses the primary lock to uniquely identify the Percolator transaction, and uses BigTable’s reliable records to record and track the entire transaction. This record can be used during failure recovery to read the state of the entire transaction.
For the detailed Percolator algorithm, refer to the original paper. The following explains the example given in the paper.
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
Bob | 6: | 6: | 6: data @ 5 |
5: $10 | 5: | 5: | |
Joe | 6: | 6: | 6: data @ 5 |
5: $2 | 5: | 5: |
As shown in Table 1, the initial state stores two rows of data: Bob and Joe. The last committed version for both is 5, and neither is currently locked. Looking at the data column gives their current state: Bob has \$10, and Joe has \$2. If there is a "valid" lock in the version range of the cell being read ("valid" is discussed later in failure recovery), the read must wait until the lock is released.
Now Bob wants to transfer \$7 to Joe. None of the read requests need to acquire locks; they query directly according to the snapshot at the current time, so they read the state in Table 1: Bob has \$10, and Joe has \$2. The transfer is then determined to be possible, and the write begins. All write requests are first buffered locally and are performed during the commit phase, which ensures that, during the commit phase, all cells that need to be locked are known. The transfer operation affects Bob’s bal and Joe’s bal respectively.
Assume we always treat the cell affected by the first write operation as the primary lock object. First, \$7 is subtracted from Bob’s account, so the first write can both acquire the primary lock and record the write request, as shown in Table 2.
There are two cases in which locking can fail:
After the transaction starts, someone else has already committed another transaction and also written to this cell, which means there is a Write-Write conflict.
Someone else has already locked this cell, and the lock is still "valid" at this time ("valid" is discussed later in failure recovery), which means Percolator Transaction is non-blocking.
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
Bob | 7: $3 | 7: I am primary | 7: |
6: | 6: | 6: data @ 5 | |
5: $10 | 5: | 5: | |
Joe | 6: | 6: | 6: data @ 5 |
5: $2 | 5: | 5: |
After the primary lock succeeds, all subsequent write operations also need to acquire locks, and the locks point to the primary lock for failure detection and recovery.
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
Bob | 7: $3 | 7: I am primary | 7: |
6: | 6: | 6: data @ 5 | |
5: $10 | 5: | 5: | |
Joe | 7: $9 | 7: primary @ Bob.bal | 7: |
6: | 6: | 6: data @ 5 | |
5: $2 | 5: | 5: |
If all write requests are locked successfully, the transaction can enter the commit phase. During commit, the content locked by the primary lock is committed first; see The transaction has now reached the commit point.
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
Bob | 8: | 8: | 8: data @ 7 |
7: $3 | 7: | 7: | |
6: | 6: | 6: data @ 5 | |
5: $10 | 5: | 5: | |
Joe | 7: $9 | 7: primary @ Bob.bal | 7: |
6: | 6: | 6: data @ 5 | |
5: $2 | 5: | 5: |
Then the content locked by the other locks is committed:
| key | bal:data | bal:lock | bal:write |
|---|---|---|---|
Bob | 8: | 8: | 8: data @ 7 |
7: $3 | 7: | 7: | |
6: | 6: | 6: data @ 5 | |
5: $10 | 5: | 5: | |
Joe | 8: | 8: | 8: data @ 7 |
7: $9 | 7: primary @ Bob.bal | 7: | |
6: | 6: | 6: data @ 5 | |
5: $2 | 5: | 5: |
Failure recovery
Percolator effectively uses the client to coordinate, but persists all required data into Bigtable through embedding. Therefore, as long as a failure can be detected, there is enough information to recover. The difficult part is how to determine that another client has really failed, and the client must follow the fail-stop model. For example, if a client is merely slow but is judged by others to have failed, then that client must stop by itself. Percolator Worker, which is the client mentioned above, uses lease reclaim based on the Chubby service[12] to provide the failure detection and fencing mechanisms described above.
The remaining problem is relatively straightforward. There are two cases based on the state of the primary lock:
If the primary lock has already committed, the transaction needs to continue rolling out, committing all cells that are found.
If the primary lock has not committed, the transaction needs to be rolled back, rolling back all cells that are found.
The paper does not mention specifically how these affected cells are discovered. Possible methods may include:
Lazily checking whether a cell needs to be rolled out or rolled back when getting data; this case must be handled.
Recording the cells affected by the transaction somewhere. Because all cells that need to be locked are already known when the primary lock is acquired, this method is feasible.
Periodically scanning the full table for cleanup.
Other optimizations
Because timestamps must be totally ordered and increasing, the Timestamp Oracle usually uses a centralized design. As a result, it may become a performance bottleneck and requires special optimization.
In Percolator, the Timestamp Oracle uses pre-allocation: it directly allocates a batch of timestamps and persists the largest one to reliable storage. This pre-allocation approach allows allocations for the next period of time to require only memory accesses. If a restart occurs, allocation can simply continue from the largest timestamp that may already have been allocated, read from reliable storage.
To save communication overhead, Percolator Worker obtains a batch of timestamps from the Timestamp Oracle through batching and aggregation.
Performance comparison
For a Percolator Transaction, without considering retries and error handling:
Each read request needs to read:
the base version range
any possible lock
the primary lock pointed to by the lock
Each write request needs to:
read
writeto check whether there is a new commit, indicating a Write-Write conflictread
lockto check for lock conflictswrite the data update and the lock
commit
This shows that read and write amplification is still quite severe. The performance comparison between Percolator and bare Bigtable is shown in Figure 8 from the paper:
| Bigtable | Percolator | Relative | |
|---|---|---|---|
Read/s | 15513 | 14590 | 0.94 |
Write/s | 31003 | 7232 | 0.23 |
Advantages and disadvantages
In my view, Percolator’s advantage is that it non-intrusively adds multi-row and multi-table transaction capability to a storage system that supports multi-versioning and row-level transactions. Its disadvantages are:
The application needs to modify the table schema.
Performance is relatively low.
Non-transactional writes cannot have any read or write conflicts with transactional writes.
Failure recovery is relatively complex.
The Timestamp Oracle may be a single point of failure.
References
[1] PENG D, DABEK F. Large-scale Incremental Processing Using Distributed Transactions and Notifications[J]. OSDI’10, 2010, 2006: 1–15.
[2] CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: A distributed storage system for structured data[J]. 7th Symposium on Operating Systems Design and Implementation (OSDI ’06), November 6-8, Seattle, WA, USA, 2006: 205–218.
[3] BERENSON H, BERNSTEIN P, GRAY J, et al. A critique of ANSI SQL isolation levels[J]. ACM SIGMOD Record, 1995, 24(2): 1–10.
[4] ADYA A. Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions[J]. 1999: 198.
[5] CROOKS N, PU Y, ALVISI L, et al. Seeing is Believing: A Client-Centric Specification of Database Isolation[J]. Podc, 2017(June): 73–82.
[6] CERONE A, BERNARDI G, GOTSMAN A. A Framework for Transactional Consistency Models with Atomic Visibility[J]. 26th International Conference on Concurrency Theory, {CONCUR} 2015, Madrid, Spain, September 1.4, 2015, 2015, 42(Concur): 58–71.
[7] BERNSTEIN P A, GOODMAN N. Concurrency Control in Distributed Database Systems[J]. ACM Computing Surveys, 1981, 13(2): 185–221. An earlier MVCC survey
[8] BERNSTEIN P A, GOODMAN N, HADZILACOS V. Concurrency Control and Recovery in Database Systems[M]. ACM Transactions on Database Systems, Addison-Wesley Pub. Co, 1987. An MVCC book
[9] WU Y, ARULRAJ J, LIN J, et al. An empirical evaluation of in-memory multi-version concurrency control[J]. Proceedings of the VLDB Endowment, VLDB Endowment, 2017, 10(7): 781–792.
[10] MOMJIAN B. MVCC Unmasked[EB/OL]. (2019). http://momjian.us/main/writings/pgsql/mvcc.pdf.
[11]Raad, A., Lahav, O., & Vafeiadis, V. (2019). On the Semantics of Snapshot Isolation. In Logic Programming (Vol. 1, pp. 1–23). Springer International Publishing. https://doi.org/10.1007/978-3-030-11245-5_1
[12] BURROWS M. The Chubby lock service for loosely-coupled distributed systems[J]. OSDI ’06: Proceedings of the 7th symposium on Operating systems design and implementation SE - OSDI ’06, 2006: 335–350.