Paper Notes: [SOSP'01] SEDA: An Architecture for Well-Conditioned, Scalable Internet Services
This article reviews how the SEDA architecture improves scalability and stability under high load through a staged event-driven design.
The staged event-driven architecture (SEDA) framework takes load and resource bottlenecks into account during modeling, so it can work well under high load and effectively prevent service overload. The basic idea of the SEDA architecture is to split business logic into a series of stages connected by queues, composing them into a data-flow network for execution.
I had read the SEDA paper a long time ago and did not pay too much attention to it at the time, because the idea was really too simple. Over the past few years, I have done some relatively in-depth work on isolation and latency stability in multi-tenant systems. After recently reading some related papers and articles, I suddenly felt something click again, so I decided to pull this paper back out and write a few words about it.
Next, we will still first follow the paper’s line of thought, and then add some other related material.
Related Work
Thread-based Concurrency
The simplest and most direct approach is to start a thread to handle each incoming request. The benefit of doing this is that the programming model is extremely simple, and issues such as scheduling and isolation are handed over to the operating system to guarantee, which is also relatively reliable. The downside is that when the load is high, it introduces non-negligible overhead. Because physical resources are limited, although the operating system provides a layer of abstraction that makes it look as if we can obtain a very large amount of resources, this is all an illusion and will be fully exposed under high load. The time slice allocated to each thread is limited; a very large number of threads perform frequent context switches; caches keep thrashing; the overhead of thread scheduling increases as the problem scale grows; and lock resources are contended. All of these factors cause performance to drop sharply. Frequent thread creation and destruction also introduce considerable overhead. Judging from the charts provided by the authors, continuing to increase pressure after exceeding the system’s capacity causes system performance to decline. We expect to use some means of self-protection so that the system can remain near its peak performance.
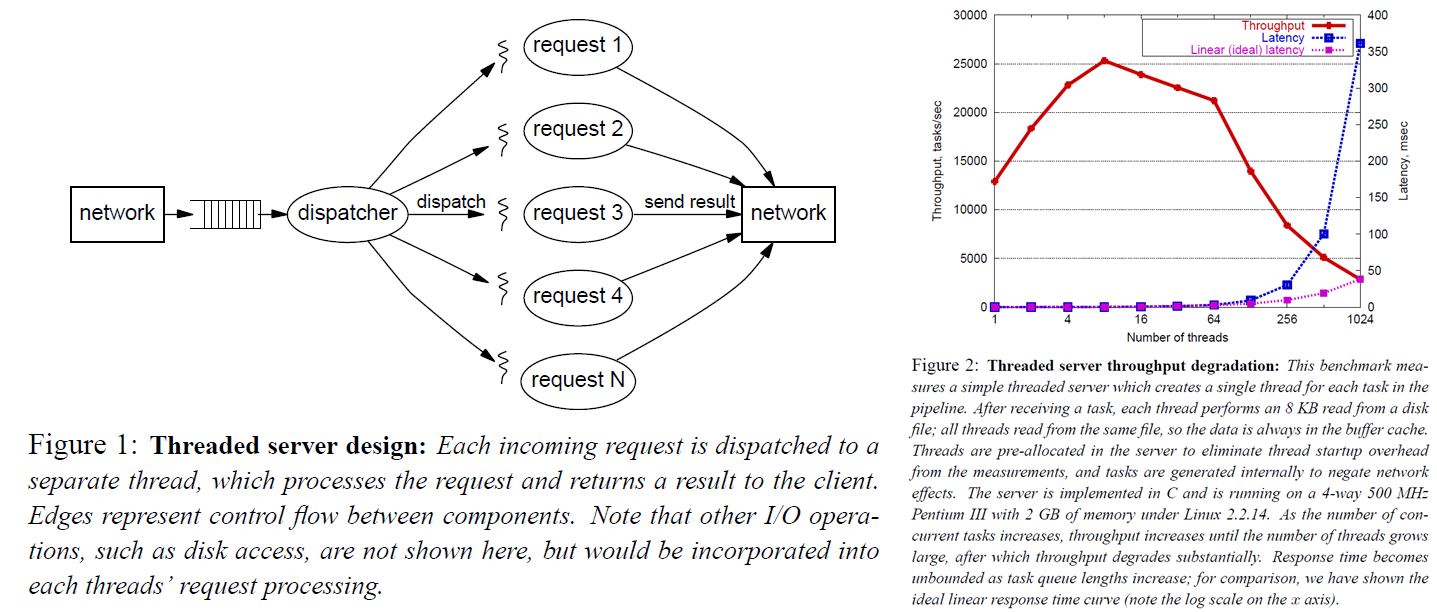
Thread-pool-based Concurrency
A simple improvement is to use a thread pool. This at least solves the problem caused by having too many threads. The authors mention here that under high load, this approach introduces fairness problems.
Fairness is indeed a very important issue in multi-tenant systems, and it is also a problem that must be faced once a system reaches a certain scale. Let me be a little wordy here and elaborate briefly. Simply put, the resource utilization of a multi-tenant service is much higher than that of a single-tenant service. When there are enough tenants, and they are sufficiently diverse, while some users are busy, there are usually also some users who are idle. This brings an improvement in overall utilization. First, we need to ensure fairness, so that one person’s unexpected use of an unusually large amount of resources does not affect other users who are using the service normally. Otherwise, because of degraded user experience, users will refuse to use your service. Going further, perhaps we need to provide tiered service for users: high-priority users can preempt resources used by low-priority users, and of course the pricing may also be tiered.
The fairness problem mentioned by the authors occurs in the following scenario. When the load is extremely high, the speed at which we process requests cannot keep up with the speed at which requests are generated. A large number of requests accumulate in the task dispatch queue, or even in the network protocol stack. In this situation, the overall latency of a newly arriving request should be the queuing latency plus the latency of actually executing the processing. The queuing latency is uncontrollable, and because the overload problem cannot be properly scheduled, this violates fairness.
I partly agree with the authors' conclusion here. From a purely theoretical perspective, there is indeed no perfect solution to this problem. From a perspective that better matches practical situations, there are actually still some things we can do, and they can achieve good results in some cases. If we consider a DoS (Denial of Service) attack, then never mind your service; even the network equipment may be overwhelmed. In that case, we already have no way to handle it well at the software layer. The more common situation is that some users have abnormal request volumes that exceed their own quotas, but do not exceed the capacity of the whole service; or they do exceed the capacity of the whole service, but not by an especially outrageous amount, for example only by one or two times (depending on the complexity of your business logic). For the former, through quota management, when this request is scheduled for processing, we can reject it, thereby avoiding the burden of executing the business logic. In this way, we can improve our system’s capacity to some extent. If the load rises further, perhaps the speed at which we reject requests cannot keep up with the speed at which requests are generated. In that case, perhaps we can adopt some NIC queue-management strategies, such as Random Early Discard, to further improve our system’s capacity (but it is already lossy at that point).
The authors also give a fairly interesting example. For instance, when the system is idle, a few relatively large requests arrive and occupy all the threads in the thread pool (but there are no subsequent queued requests). Then a bunch of small requests suddenly arrive. Although we could handle them if we had just one more idle thread, now none of the active threads can get to this work in time, and the waiting queue is blown up. This may require more refined policy tuning on a case-by-case basis, such as classifying requests by size to avoid one type of request occupying all active threads.
This paper was written relatively early, and it mainly investigated topics related to HTTP servers, so I feel the model and data processing may indeed both be relatively simple. Therefore, a lot of the time, when people talk about the thread-pool model, it may really mean directly putting requests into the thread pool and running them, without considering more design aspects.
Event-driven Concurrency
Judging from the authors' broad description, this feels like a traditional event model driven by epoll. Almost all blocking I/O is converted into events, which are then delivered to each submodule for further processing. Each submodule uses a state machine to manage its own state, so the request context is managed by the state machine instead of being placed directly on the thread context. This model is obviously much more complex than the multithreaded model.
Each submodule needs to carefully maintain the request context
All business logic needs to avoid blocking as much as possible; otherwise, it may block the event dispatcher
Each newly added submodule may require modifying the event dispatcher’s logic, especially the logic for scheduling events (for example, aggregating a batch of the same type of event and processing them together may increase the cache hit rate and thus improve efficiency)
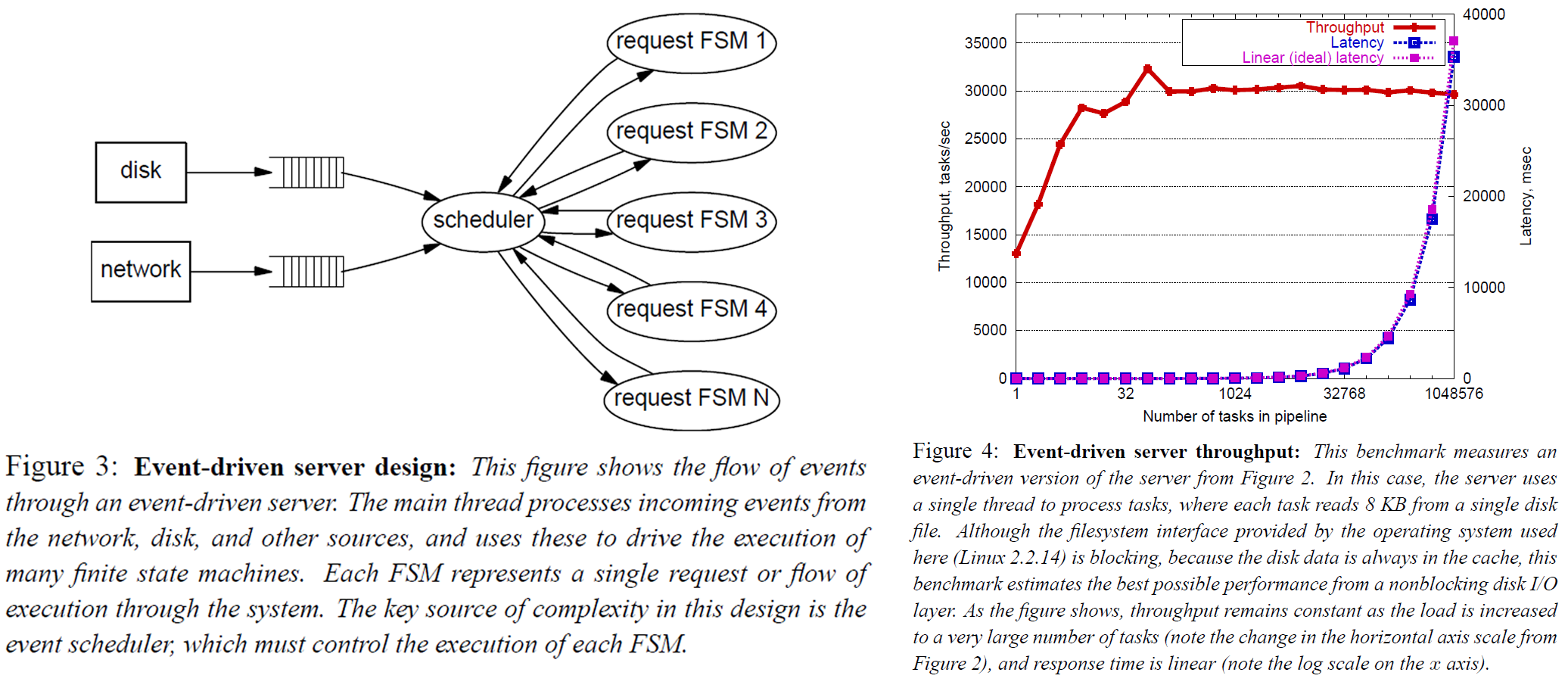
Structured event queues
This section introduces some improvements to event-driven concurrency. It only says a little about them in general, and I did not see anything particularly valuable, so I will skip it for now.
The Staged Event-Driven Architecture
So overall, the event-driven architecture is better in terms of performance, but the programming complexity also increases significantly. Is it possible to create a model that balances performance and development convenience? That is the SEDA proposed by the authors. SEDA considers these aspects:
Support high concurrency and high load (using the performance advantages brought by event-driven design as much as possible)
Simplify the difficulty of building the system
Allow the system to sense the current load and make adjustments accordingly (for example, degrading some requests, and so on)
Give the system a certain degree of self-tuning capability (for example, the size of the thread pool used by each stage is not specified statically, but is automatically adjusted according to load and other conditions)
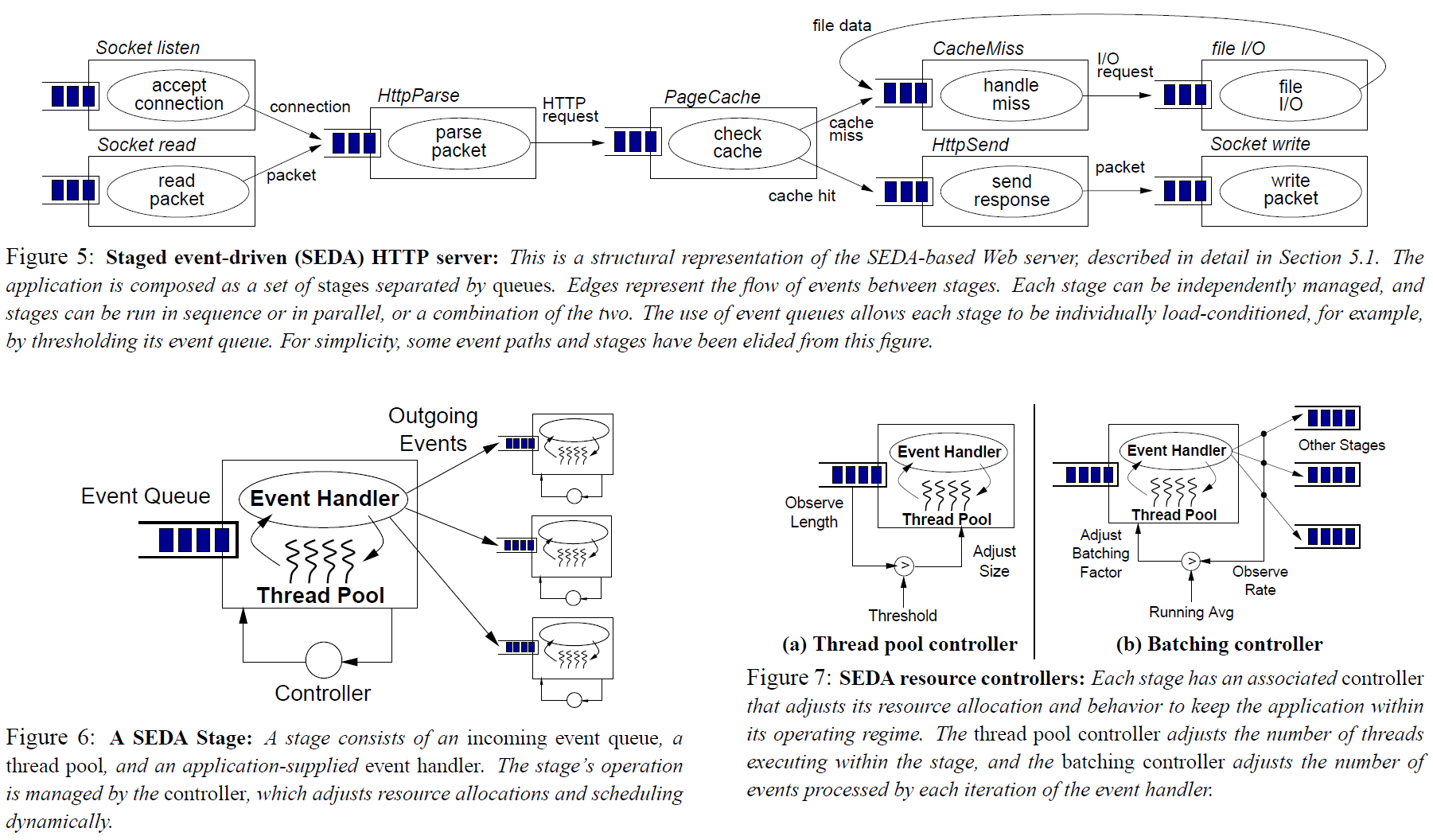
There is not much to say about the architecture itself, because the paper also does not say how to divide stages reasonably. Everyone can go by feel… According to my personal understanding, stages may need to be divided in the following places.
Different degrees of concurrency are needed
Logical branching is needed
Internal retries are needed, but there are asynchronous operations inside, so they can only be done in a way similar to requeuing
It is logically necessary to split things apart here
This approach is somewhat similar to the actor model (I will not expand on the actor model here; those interested can read the documentation for Akka and Erlang). However, the traditional actor model attaches threads to actors rather than to mailboxes. It does seem more reasonable to attach compute resources to queues, or to schedulers. Apache Hadoop and Microsoft Orleans seem to do this.
The authors mentioned in the paper whether it is better to put an event queue between stages or to directly use a subroutine call. The paper says this is mainly for decoupling. But later, in the retrospective [2], it says that this is actually the essence: load and resource bottlenecks must be modeled in the architecture (that is, in the event queue here) in order to solve the problem of abnormal system behavior when load is high and resources are insufficient. I personally agree with this very much.
The paper also mentions that thread pools can self-tune. It says here that the number of threads in the thread pool and the batch size for a single execution can be adjusted. Thread pools with autoscaling capabilities are not actually that rare, but APIs that consider batch execution at the API design stage are relatively uncommon. From my personal experience, batch execution can indeed significantly improve compute capacity, mainly considering these aspects.
Less lock contention (acquire the lock once to run a batch of data instead of just one item)
Better reuse of some temporary resources
Better cache utilization
Potential benefits from SIMD instruction sets
In some special scenarios, more complex strategies may also be used. For example, [3] uses a more complex global strategy to optimize overall, end-to-end compute latency.
The later parts of the paper also include some details, such as asynchronous I/O, degradation strategies, and so on. They are not strongly related to this core idea, so I will not expand on them.
A Retrospective on SEDA
At the beginning, it briefly discusses the history, mainly saying that the points the paper focused on at the time and the points people focus on now may differ in some places. It also says that this paper is about architecture rather than implementation, so people should not compare pears with apples.
What Went Wrong
First, there is nothing wrong with the stage abstraction; it nicely isolates different modules. But not every stage needs to be bound to a thread pool. In some places, it may be more reasonable to combine stages and run them on a single thread pool (concurrency boundaries). Where a thread pool is not needed, an event queue is not needed either; direct method calls are more efficient. I do not think this needs much explanation. The main point is that most of the time the system runs under low load, and creating several thread pools and event queues for no reason is already pretty strange. Moreover, the stage abstraction itself is a logical abstraction, so it is also strange to insist on binding it to a thread pool.
Then it discusses some implementation details. At that time, Java did not yet have non-blocking I/O. In short, this aspect is not important, so I will not talk about it.
What Went Right
Writing it in Java was absolutely the right choice (routine teasing of C/C++)!
Consider load and resource bottlenecks during modeling. One reason is that you can intuitively see where the bottleneck is (you only need to see where the queue is long). Another reason is that your service cannot merely run normally under low load and then fall over as the load approaches its limit.
Other Notes
It also says that test suites are very important. Some test suites simply do not consider high-load situations at all. They also do not consider testing memory bottlenecks, I/O bottlenecks, socket pressure, and so on. In any case, this is basically a complaint about test design. Everyone should take it as a warning when doing performance testing, and should not blindly trust test data obtained in such specific scenarios; its reference value is relatively limited.
References
[1] Welsh M, Culler D, Brewer E. SEDA: An architecture for well-conditioned, scalable internet services[J]. ACM SIGOPS operating systems review, 2001, 35(5): 230-243.
[2] Welsh M. A Retrospective on SEDA. https://matt-welsh.blogspot.com/2010/07/retrospective-on-seda.html
[3] Xu L, Venkataraman S, Gupta I, et al. Move fast and meet deadlines: Fine-grained real-time stream processing with cameo[C]//18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21). 2021: 389-405.