Paper Notes: [CONCUR'15] A Framework for Transactional Consistency Models with Atomic Visibility
This article introduces the formal framework of a paper on transactional consistency models and explains the intuitive meaning of concepts such as atomic visib…
In the database field, Transaction is a very important abstraction. Its key purpose is to ensure the correctness of concurrent requests. Because Serializability-level consistency comes at a relatively high cost, weaker consistency levels are usually used in exchange for better performance. In particular, in some special scenarios, using weak consistency does not introduce errors. Unfortunately, ANSI SQL’s classification of consistency levels is still not detailed enough; in particular, it lacks formal specifications for some common weak consistency implementations. This makes it difficult to confirm whether a weak consistency implementation provided by a specific vendor truly will not introduce errors in a specific scenario.[2]
In recent years, there have been a number of papers that use formal methods to analyze Transaction consistency, such as [3][4], as well as [1], which this article aims to introduce. Formal descriptions help with reasoning and verification, but informal explanations are still needed for intuition. This article will introduce the formal work done in [1] and explain its intuitive meaning.
Basic Model
[1] uses the Abstract Executions model to analyze Transactional consistency.
Assume the database is a collection of slots. Each slot can store an integer, and there are two kinds of operations on the database: reads and writes:
If we assign a unique identifier to each operation, we can obtain some history events:
Further, we can define a Transaction:
A transaction $T, S, \ldots$ is a pair $(E, \mathrm{po})$, where $E \subseteq \mathrm{HEvent}$ is a finite, non-empty set of events with distinct identifiers, and the program order $\mathrm{po}$ is a total order over $E$. A history $\mathcal{H}$ is a (finite or infinite) set of transactions with disjoint sets of event identifiers.
All transactions in a history are assumed to be committed: to simplify presentation, our specifications do not constrain values read inside aborted or ongoing transactions.
Simply put, a Transaction is a set of history events with a total order relation (plus some additional conditions for rigor, which are not meaningful for intuitive understanding). A history consists of a set of committed Transactions.
Going one step further, we can define an abstract execution:
We call a relation prefix-finite, if every element has finitely many predecessors in the transitive closure of the relation.
An abstract execution is a triple $\mathcal{A} = (\mathcal{H}, \mathrm{VIS}, \mathrm{AR})$ where:
visibility: $\mathrm{VIS} \subseteq \mathcal{H} \times \mathcal{H}$ is a prefix-finite, acyclic relation; and
arbitration: $\mathrm{AR} \subseteq \mathcal{H} \times \mathcal{H}$ is a prefix-finite, total order such that $\mathrm{AR} \supseteq \mathrm{VIS}$.
The intuitive meaning of an abstract execution is less obvious; we can only regard it as a history with two ordering relations. However, the concrete meanings of $\mathrm{VIS}$ and $\mathrm{AR}$ are not defined here. The paper only gives a rough explanation of their intuition:
$T \stackrel{\mathrm{VIS}}{\longrightarrow} S$ can roughly be understood as $S$ having discovered $T$; generally, $S$ read content produced by $T$.
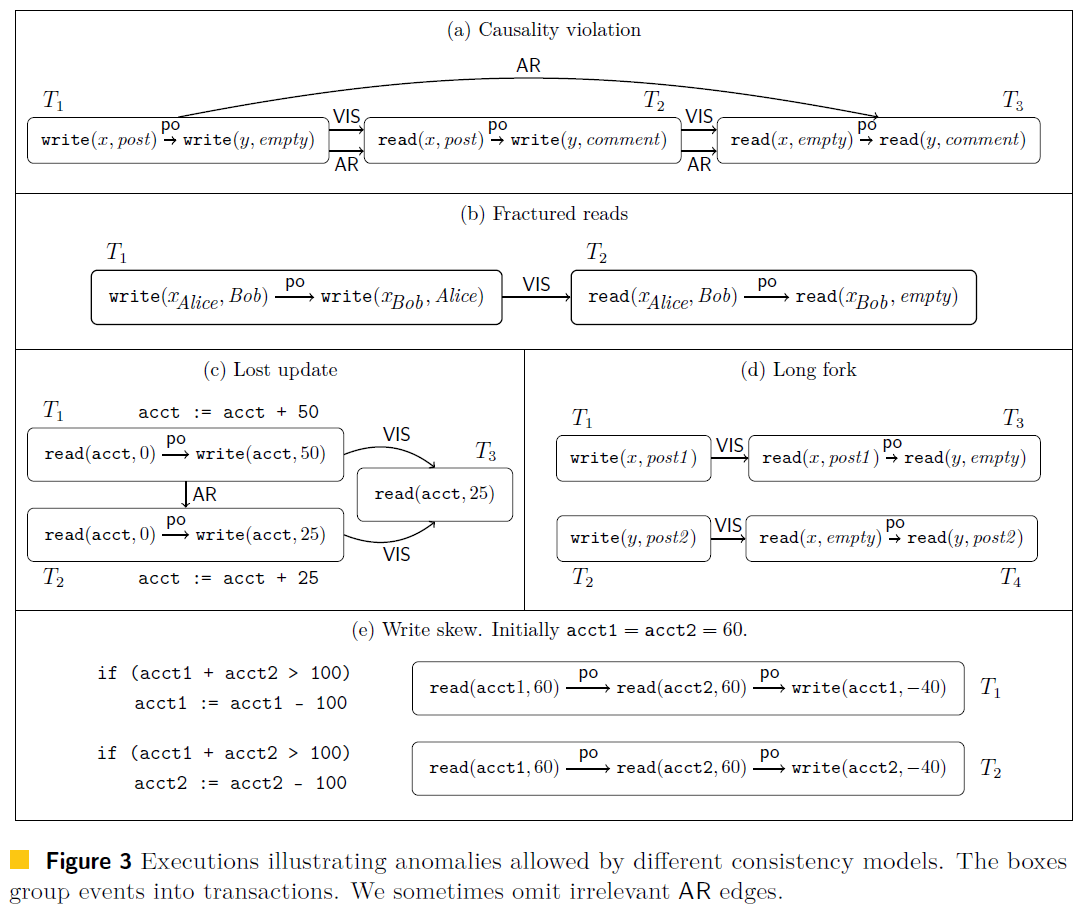
$T \stackrel{\mathrm{AR}}{\longrightarrow} S$ can roughly be understood as the content written by $S$ (partially or entirely) overwriting the content written by $T$. Although this is how the paper explains it, I think the following interpretation reads more smoothly: $S$ “actually” happened after $T$. I think this interpretation is more appropriate because in Figure 3(a) of the paper there is $T_1 \stackrel{\mathrm{AR}}{\longrightarrow} T_3$ (this relation comes from $\mathrm{AR}$ being transitive and reflexive), but $T_3$ does not perform any write operation at all. Under the original paper’s wording, this is impossible to understand.
$\mathrm{AR} \supseteq \mathrm{VIS}$ means $( (T \stackrel{\mathrm{VIS}}{\longrightarrow} S) \Rightarrow (T \stackrel{\mathrm{AR}}{\longrightarrow} S)) \land ( (T \stackrel{\mathrm{AR}}{\longrightarrow} S) \nRightarrow (T \stackrel{\mathrm{VIS}}{\longrightarrow} S))$. In other words, I may overwrite something you wrote without knowing about you; alternatively, although I “actually” happened before you, you do not know that I happened before you. Or we can regard $\mathrm{VIS}$ as removing some elements from $\mathrm{AR}$.
In fact, $\mathrm{VIS}$ and $\mathrm{AR}$ are determined by the constraints of the consistency model, which is why no precise definition is given here. The method used in this article is to exclude certain counterintuitive cases from abstract executions by adding constraints to $\mathrm{VIS}$ and $\mathrm{AR}$. The added constraints are defined as certain (good) properties, and consistency models are then defined by composing these properties.
In short, an abstract execution $\mathcal{A}$ is an event history $\mathcal{H}$ with two ordering relations, $\mathrm{VIS}$ and $\mathrm{AR}$. Here, $\mathrm{AR}$ is the order in which committed transactions are “actually” serialized and take effect, while $\mathrm{VIS}$ is the logical causal relationship between transactions that can be discovered from the user’s (client’s) perspective.
The concepts of the abstract execution model are not described in much detail in the paper. If you are interested in this part, I recommend reading [5]. However, note that the abstract execution model described in detail in [5] differs from this scenario: it is built on operations, whereas the abstract execution in [1] is built on transactions.
Summary of Consistency Models and Properties
The consistency models mentioned in the paper are shown in figure 1.
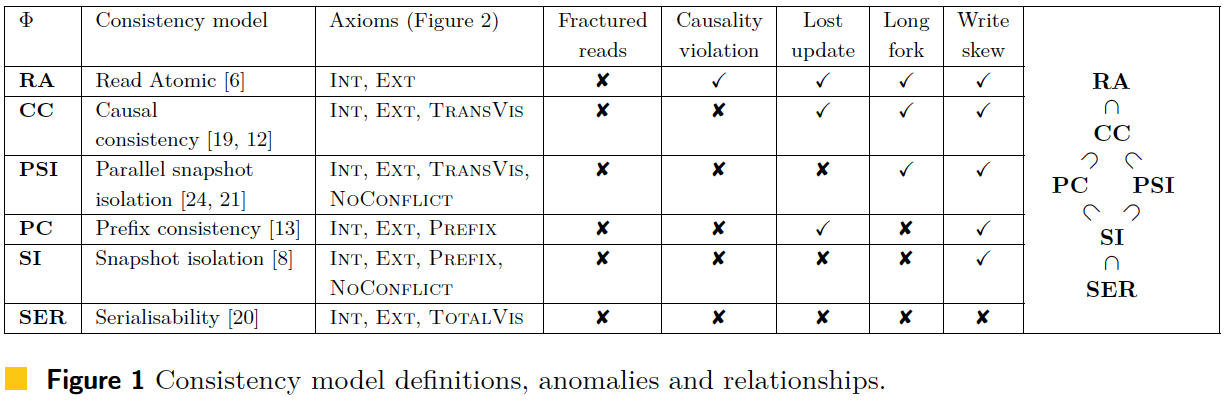
Several consistency levels commonly seen in ANSI SQL are not mentioned there:
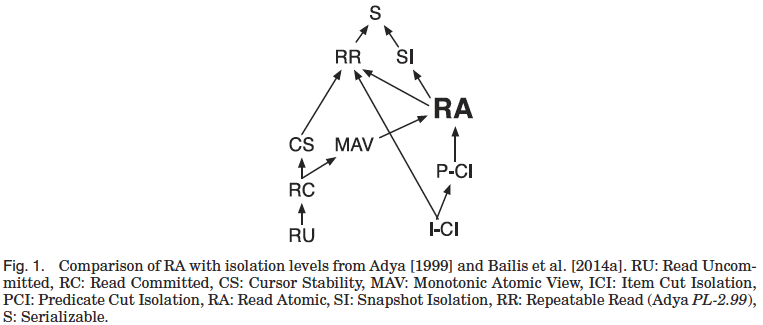
In particular, Repeatable Read and Read Atomic are quite similar and can easily cause confusion, but they are not the same consistency level. See [6]'s RAMP figure 1 (note that this is TODS 2016, not the SIGMOD 2014 paper with the same title).
Some Notation
For convenience of presentation, the paper also defines some notation.
$R^{-1}(u)$
For a relation $R \subseteq A \times A$ and an element $u \in A$, we let $R^{−1}(u) = \{ v \mid (v, u) \in R \}$.
Intuitively, $R^{-1}$ is the reverse order of $R$, but note that $R$ may be a partial order.
For example, the reverse order of the program order $\mathrm{po}$ inside a Transaction mentioned above is $\mathrm{po}^{-1}$.
$\max_\mathrm{R}(A)$ and $\min_\mathrm{R}(A)$
For a total order $\mathrm{R}$ and a set $A$, we let $\max_\mathrm{R}(A)$ be the element $u \in A$ such that $\forall v \in A. \ v = u \lor (v, u) \in R$; if $A = \emptyset$, then $\max_\mathrm{R}(A)$ is undefined. In the following, the use of $\max_\mathrm{R}(A)$ in an expression implicitly assumes that it is defined.
Intuitively, $\max_\mathrm{R}(A)$ ($\min_\mathrm{R}(A)$) represents the last (earliest) element of the non-empty set $A$ under the order relation $\mathrm{R}$.
For example, $\max_{\mathrm{po}}(T_1)$ in figure 3(e) is $\mathrm{write}(\text{acct1}, -40)$.
$T \vdash \mathrm{Write} \ x : n$ and $T \vdash \mathrm{Read} \ x : n$
defining certain attributes of a transaction $T = (E, \mathrm{po})$. We let $T \vdash \mathrm{Write} \ x : n$ if $T$ writes to $x$ and the last value written is $n: \max_\mathrm{po}(E \cap \mathrm{WEvent}_x) = (\_, write(x, n))$.
Intuitively, $T \vdash \mathrm{Write} \ x : n$ ($T \vdash \mathrm{Read} \ x : n$) means that among the Events inside Transaction $T$, according to program order, the last (earliest) write (read) to $x$ is $n$.
For example, in figure 3(e), $T_1 \vdash \mathrm{Write} \ \text{acct1} : -40$.
Read Atomic
First, let’s look at several basic properties and some weaker isolation levels mentioned in the paper. The weakest isolation level introduced in the paper is Read Atomic (RA), but as shown in RAMP figure 1, this isolation level is still higher than several weaker isolation levels defined in ANSI SQL, and RA and RR are two slightly different isolation levels. Comparing the relationships between RA and RU/RC/RR, as well as the various properties defined in [1], involves how to formally express RU/RC/RR and how these definitions relate to the various properties. Due to space constraints, this article does not explain that; if you are interested, you can find the related content in Section 3.3 of [6].
Informally, RA does not allow fractured reads [6]:
Definition 3.1 (Fractured Reads). A transaction $T_j$ exhibits the fractured reads phenomenon if transaction $T_i$ writes versions $x_a$ and $y_b$ (in any order, where $x$ and $y$ may or may not be distinct items), $T_j$ reads version $x_a$ and version $y_c$, and $c < b$.
[1] first introduces two basic properties: the internal consistency axiom (INT) and the external consistency axiom (EXT).
Intuitively, the INT property guarantees that, within a Transaction, if reading $x$ returns $n$, then if there is a previous operation on $x$ in the same Transaction, it must be $\operatorname{read}(x, n)$ or $\operatorname{write}(x, n)$. Therefore, it is called the internal consistency axiom.
In particular, the INT property guarantees that once a value has been read, no matter how many times it is read later, as long as no write operation is inserted in between, that value will not change. That is, it rules out the possibility of unrepeatable reads.
Intuitively, the EXT property guarantees that the first operation in $T_1$ to read $x = n$ does so because, if there exists a $T_0$ that is a previous Transaction of $T_1$ in the $\mathrm{VIS}$ order, then the last write to $x$ in $T_0$ wrote $n$; otherwise, $n = 0$ (the initial value was read). Because $\mathrm{VIS}$ is a partial order, there may be more than one such Transaction $T_0$; in that case, we take the latest one among them in the $\mathrm{AR}$ order. The EXT property guarantees that the first read of the value of $x$ is due to some “previous” other Transaction writing it, so it is called the external consistency axiom.
In particular, the EXT property guarantees that dirty reads will not occur, because Transactions that have not committed (whether aborted or ongoing) do not appear in the abstract execution (this is not entirely rigorous, because without the INT property there is no guarantee that arbitrary strange results cannot be read in the middle). Therefore, this property already exceeds the requirements of Read Committed (this is my own somewhat imprecise conclusion; the imprecision lies in not specifying properties related to dirty writes).
In addition, the EXT property guarantees atomic visibility: either all or none of its writes can be visible to another transaction. This is also why this isolation level is called Atomic Read. It guarantees that fractured reads will not occur, so it can be used in scenarios that require integrity checks, for example:
$T_1$ writes that Alice and Bob have become friends bidirectionally, so a later $T_1$ will not observe only a unidirectional relationship; see Figure 3(b)
Secondary Index scenarios
Causal consistency
Although Read Atomic is already a relatively strong consistency level, it can guarantee only that the content written in one Transaction is always seen together by other Transactions (no one sees only part of it, i.e., fractured reads). It cannot guarantee under what circumstances those writes will be observed. This means two things:
Even after enough “real time” has passed, the write may still not be discovered. In the extreme case, we can implement a trivial database where all writes in fact never take effect. For extended discussion on this topic, see [8].
It may violate causal relationships. For example, in Figure 3(a), $T_3$ has already read $\operatorname{write}(y,\text{comment})$ written by $T_2$, so it should also be able to read $\operatorname{read}(x,\text{post})$ that $T_2$ read.
Causal consistency requires that causal relationships not be violated. In the current model, $\mathrm{VIS}$ effectively captures causal relationships, so causal consistency can be guaranteed simply by requiring $\mathrm{VIS}$ to be transitive, namely the TRANSVIS property in Figure 1.
Parallel snapshot isolation
As discussed in [4], Causal consistency is the highest consistency level that can achieve 100% High Availability. This means Causal consistency can be implemented without any communication between Replicas, which may lead to the lost update[2] problem:
P4 (Lost Update): The lost update anomaly occurs when transaction $T_1$ reads a data item and then $T_2$ updates the data item (possibly based on a previous read), then $T_1$ (based on its earlier read value) updates the data item and commits.
For example, although Figure 3(c) satisfies causal consistency, $T_1$'s $\operatorname{write}(\text{acct}, 50)$ is overwritten. To constrain this situation, we introduce the NOCONFLICT property:
Intuitively, if $T$ and $S$ both write to the same object, then these two Transactions cannot be Concurrent; one of them must know that the other committed before it. This prevents one write from overwriting the other.
Prefix consistency
TRANSVIS guarantees that every node in a chain with causal relationships can observe all causal relationships before it. However, if two chains with no causal relationship between them appear from the beginning, some strange phenomena can occur. The root cause of these phenomena is that writes do not become visible to other Transactions within a bounded amount of time[unbounded-staleness]. For example, in Figure 3(d), $T_1$ and $T_2$ write $x$ and $y$ respectively, $T_3$ sees the write to $x$ but not the write to $y$, and $T_4$ sees the write to $y$ but not the write to $x$. We can forbid this situation by strengthening TRANSVIS with PREFIX:
If $T$ observes $S$, then it also observes all $\mathrm{AR}$-predecessors of $S$.
Here, observes means $\mathrm{VIS}$. Because $\mathrm{AR}$ is transitive, the PREFIX property implies the TRANSVIS property. More formally:
This means that for the Transactions visible to $T$, all Transactions before their “actual commit” and the “actual commit” relationships among them are also visible.
Snapshot isolation
As shown in [figure-1], Snapshot isolation has the INT, EXT, PREFIX, and NOCONFLICT properties.
Snapshot Isolation and Repeatable Read differ slightly[6] (Remark 9 in [2] also compares the two, but its model is not as detailed as [6]'s):
Definition 3.16 (Snapshot Isolation). A system provides Snapshot Isolation if it prevents phenomena G0, G1a, G1b, G1c, PMP, OTV, and Lost Updates.
Definition 3.20 (Repeatable Read). A system provides Repeatable Read isolation if it prevents phenomena G0, G1a, G1b, G1c, and Write Skew for nonpredicate reads and writes.
Serializability
Although Snapshot Isolation is already a fairly strong consistency level, problems can still occur at certain times, such as the write skew problem described in Figure 3(e). Both $T_1$ and $T_2$ check that the sum of the balances of two accounts is greater than 100, and each withdraws 100 from one of the accounts. Because $T_1$ and $T_2$ execute concurrently, both checks can pass at the time of checking. Because $T_1$ and $T_2$ operate on different accounts, they also do not violate the NOCONFLICT property. However, in the end, the results of both $T_1$ and $T_2$ will cause the initial check constraint to be bypassed, and the total amount across the two accounts becomes negative.
For this, we can use the TOTALVIS property as a restriction, namely making VIS a total order. Considering that $\mathrm{AR} \supseteq \mathrm{VIS}$, we have $\mathrm{AR} = \mathrm{VIS}$, which is Serializability.
Appendix
Summary
This paper is very helpful for modeling and understanding relatively strong consistency, but its drawback is that the model is not detailed enough, so some consistency levels cannot be represented or distinguished, and some anomaly cases are not listed. Still, it is sufficient for most common cases.
Some content about refinement correctness and equivalence with other models is omitted later, as it is not very meaningful for engineers.
Digression
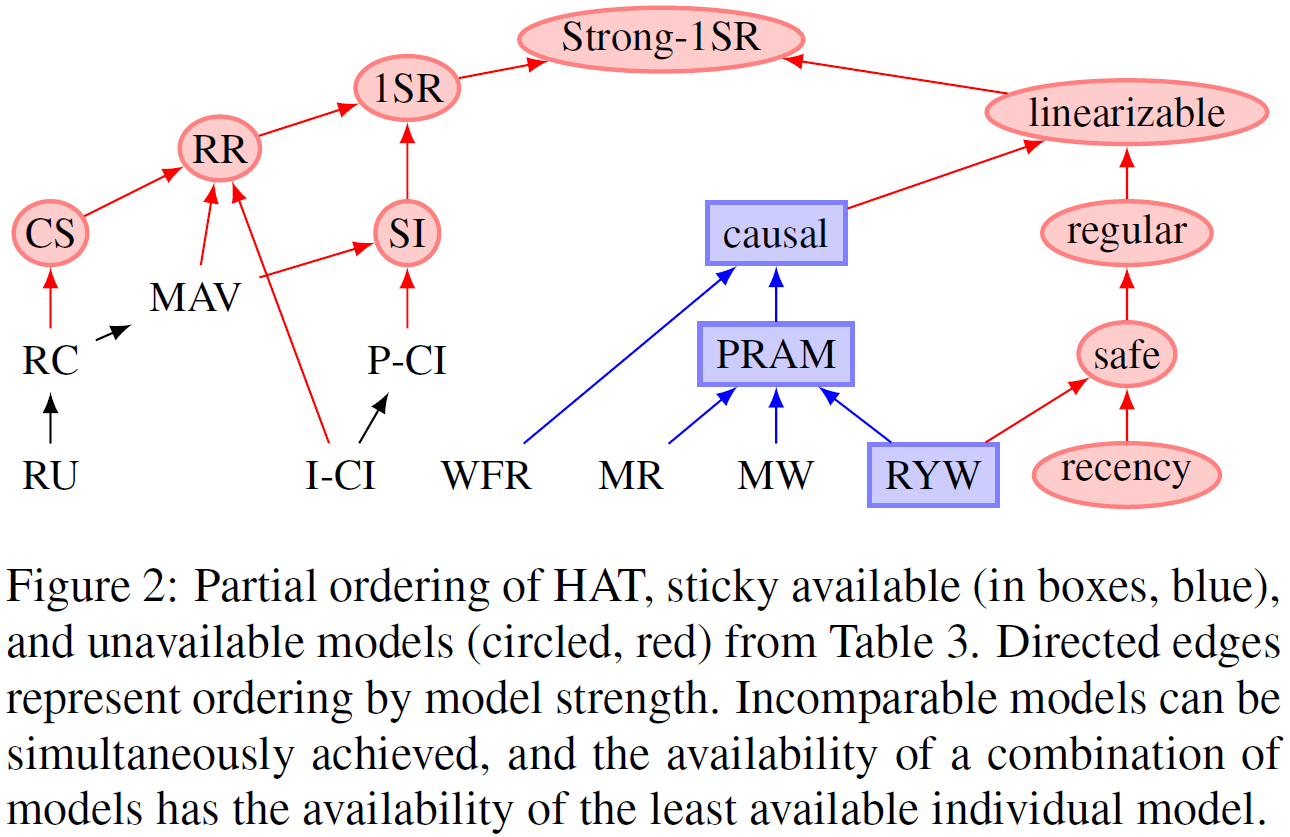
As shown in [4]'s HAT Figure 2, the left half mainly contains consistency levels related to coordination among multi-key operations, while the right half mainly contains consistency levels related to coordination among single-key multi-replica operations, but there is also overlap between the two. This paper mainly discusses Transaction consistency models; for consistency models related to replication, see [9].
References
[1] Cerone, A., Bernardi, G., & Gotsman, A. (2015). A Framework for Transactional Consistency Models with Atomic Visibility. 26th International Conference on Concurrency Theory, {CONCUR} 2015, Madrid, Spain, September 1.4, 2015, 42(Concur), 58–71. https://doi.org/10.4230/LIPIcs.CONCUR.2015.58
[2] BERENSON H, BERNSTEIN P, GRAY J, et al. A critique of ANSI SQL isolation levels[J]. ACM SIGMOD Record, 1995, 24(2): 1–10.
[3] ADYA A. Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions[J]. 1999: 198.
[4] Bailis, P., Davidson, A., Fekete, A., Ghodsi, A., Hellerstein, J. M., & Stoica, I. (2013). Highly Available Transactions: Virtues and Limitations. Proceedings of the VLDB Endowment, 7(3), 181–192. https://doi.org/10.14778/2732232.2732237
[5] BURCKHARDT S. Principles of Eventual Consistency[J]. Foundations and Trends® in Programming Languages, Hanover, MA, USA: Now Publishers Inc., 2014, 1(1–2): 1–150.
[6] Bailis, P., Fekete, A., Ghodsi, A., Hellerstein, J. M., & Stoica, I. (2016). Scalable Atomic Visibility with RAMP Transactions. ACM Trans. Database Syst., 41(3), 15:1—15:45. https://doi.org/10.1145/2909870
[7] ADYA A, LISKOV B, O’NEIL P. Generalized isolation level definitions[C]//Proceedings of 16th International Conference on Data Engineering (Cat. No.00CB37073). IEEE Comput. Soc, 2002(March): 67–78.
[8] BAILIS P, VENKATARAMAN S, FRANKLIN M J, et al. Quantifying eventual consistency with PBS[J]. The VLDB Journal, 2014, 23(2): 279–302.
[9] VIOTTI P, VUKOLIĆ M. Consistency in Non-Transactional Distributed Storage Systems[J]. ACM Computing Surveys, 2016, 49(1): 1–34.