论文笔记:[Operating Systems Review 2007] Autopilot: Automatic Data Center Management
本文概述微软 Autopilot 集群管理系统的设计目标,以及机器生命周期、应用部署和自动化运维机制。
Autopilot是微软Bing组研发的集群管理系统,至今已有近20年的历史。Autopilot是一个内部模块高度解耦,完善发达的系统,其设计目标是自动化的管理静态集群。自动化的好处有以下几点:
节省人力
响应速度和处理时间优于人工处理
所有的处理过程都有Audit
不易出错
Autopilot的设计依赖于这样一个前提:运行的应用的进程可以在不被预先通知的情况下杀死,而不影响整个系统的稳定性。这一假设是合理的,因为使用的物理机是通用计算机(对比商业高可靠计算机,超级计算机等),其随时有可能发生故障,因此集群管理系统并不能保证在节点失效前对运行的进程进行通知。 集群管理系统主要需要考虑以下3个方面:
机器的生命周期管理
应用的生命周期管理
两者的匹配
机器和应用生命周期的匹配
Autopilot是一个静态的管理系统,这个静态的最主要体现就是机器和应用的生命周期是静态绑定的。Autopilot首先将机器划分为不同的Machine type,这决定了这台机器是用于安装那些应用的(纵向切分);其次将同一Machine type的机器又划分了Scale unit,决定了相同用途的机器的管理批次顺序(横向切分)。
有时,机器的生命周期长于应用的生命周期。如果是软件故障,则会通过Reboot,Reimage,Rollback等机制将其恢复正常。如果是应用升级或降级,则按照Machine type和Scale unit将受影响的机器分成不同的stage分别按顺序进行操作。如果需要将机器改作它用,则需要重新指定机器的Machine type和Scale unit。
有时,机器的生命周期短于软件的生命周期。此时通过Replace操作替换物理机。
系统架构
Autopilot的系统架构如下(根据个人对论文的理解加工而成):
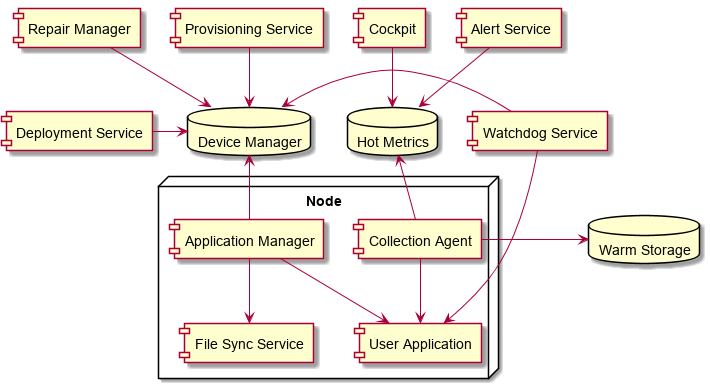
集群中的所有节点状态由统一的中心数据库Device Manager进行记录。这一中心数据库使用Paxos协议实现,提供Linearizability一致性,一般由5-10台机器组成,类似于Zookeeper。集群中的所有组件都依赖于Device Manager中记录的信息,相互之间不进行直接的交互。这样的设计方式使得组件之间完全解耦,但是对Device Manager的依赖非常重。
每个节点上由Application Manager进行主要的管理工作:
与Device Manager通信决定应该保留哪些应用的数据
通过File Sync Service下载所需的文件
将标记为Active的Application启动
应用和机器的状态信息通过Watchdog Service收集并记录到Device Manager中。日志和Performance Counter通过Collection Agent收集到冷热存储中。
Device Manager是整个集群的核心。Application Manager是每台机器的核心。
机器的生命周期管理
这一点是很多软件工程师都不太了解的"神秘领域",这一点论文中进行了一些细致描述。机器被插入机架后,可以通过每个机架上自带的控制单元进行基本的电源管理,可以远程开关机、重启而无需人工到指定位置进行物理操作。集群中所有的机器都会被Provisioning Service定期检查,以识别其是否是新加入集群的机器,基本运行信息是否正确(如操作系统,BIOS版本等)。如有需要,Provisioning Service会自动重新启动该机器,机器在启动时会进入PXE Network Booting,具体使用的PXE image由Provisioning Service决定。在此过程中,首先联系Device Manager决定该完成何种操作,然后自动化的进行BIOS升级,Reimage等底层操作。
Reimage使用的镜像是定制过的,其中直接包含了最初始的Application Manager,File Sync Service,Collection Agent等基础服务。系统在启动过后,就可以依赖于常规机制进行应用级别的组件升级和替换。
软件的生命周期管理
由于Autopilot是由Bing组研发的,在其构建之初就考虑到了在线服务对延迟敏感的特性,因此File Sync Service就很有必要了。系统不提供直接的接口,如SAMBA,FTP,RSYNC,SCP等方式进行文件传输,所有的跨节点运维交互都需要通过File Sync Service,这样的好处有2点:
可以有效的通过限流,QoS等手段避免对在线服务的影响
可以使用P2P技术减轻对数据源的压力
所有的应用需要提前进行构建操作,构建的结果成为一个manifest。论文中没有直接对其所包含的内容进行描述,但是综合提到的信息进行推断,至少包含以下内容:
应用,数据和配置文件
应用描述信息,以确定该应用是一个Always Running的服务,还是一个定期任务
以上所有内容的强校验信息,用于传输错误检测和人工修改检测
Manifest分为至少2种状态:disabled和enabled。Application Manager在与Device Manager的定期通信中得知其需要保存哪些Manifest以及它们的状态,通过File Sync Service得到所需的Manifest,将disabled状态的应用杀死,将enabled状态的应用启动。Application Manager会定期校验Manifest的完整性,并进行纠正。这样做允许同时保留一个应用的多个版本,用于接下来的升级或回滚。校验完整性除了可以克服TCP协议的弱CRC校验和存储错误导致的文件损坏,还可以避免因人工修改导致的配置文件漂移。
系统需要知道机器和应用的状态,从而进行自动修复,这是通过Watchdog Service来实现的。Watchdog Service可以和应用Cohost,也可以完全部署于其他节点,两者也可以结合使用。使用单独的Watchdog Service可以允许用户根据自己应用的逻辑来对应用的状态进行检测,这种检测有时需要以内部的视角观察应用的状态,有时需要以外部的视角(用户的身份)进行观测。用户可以自行制定修复逻辑,否则系统只能进行与应用程序自身逻辑无关的修复工作,即Reboot,Reimage,Replace等操作。
应用程序在运行的过程中,会产生日志和Metric两类信息,这些信息会通过Collection Agent收集起来,根据热度进入不同的路径,并对接报警系统或查询系统。
应用的部署流程根据论文中的内容推测如下:
用户提交部署请求
系统根据请求将应用打包成Manifest
Deployment Service将Manifest信息更新到Device Manager中
Deployment Service通知Application Manager与Device Manager进行数据同步
未能通知到的Application Manager在与Device Manager的定期同步中会得到最新信息
大部分受影响的节点下载了Manifest后开始部署流程
Deployment Service按照Machine type和Scale unit将部署操作分为不同的stage,按照顺序更新Device Manager
每个stage在进行部署前,先将受影响的机器状态设置为Probe状态,然后进行更新
Stage内有足够多的机器更新成功,并从Probe状态进入Normal状态后,认为该Stage更新成功,否则按照Stage的反顺序进行回滚
其他细节
配置文件的更新也需要走正式的部署流程,这样的好处是配置文件引发的错误也可以被自动检测和修复。类似的,操作系统的更新也是如此。
It is vital to keep checksums of all crucial files
TCP/IP checksums are weak
Computers will spontaneously start running very slowly, but keep making progress
Throttling and load shedding are crucial in all aspects of an automated system
Failure detectors must be able to distinguish between then symptoms of failure and overloading